
前言#
承接上篇 [Security] CSS injection 與純 HTML 攻擊手法,此篇主要敘述的是《Beyond XSS:探索網頁前端資安宇宙》 4–1 章節的筆記,若有錯誤歡迎大家回覆告訴我~
4–1 ~ 4–3 章節剛好也是我在讀書會負責導讀的章節,有另外做一份簡報,也可以參考看看簡報,雖然內容大同小異,簡報連結點此🔗。
Same-origin policy 與 site#
我們很常聽到瀏覽器同源政策(Same-origin policy)這個詞,這在前端和資安領域都很重要,但 origin 是什麼?site 又是什麼?像是 XSS 的 XS 是指 cross-site,CSRF 的 CS 也是指 cross-site,這篇就是要來好好搞懂這些名詞~
先備知識:URL 與 domain 的組成
在介紹 origin 和 site 之前,需要先認識 URL 和 domain 的組成,因為接下來就會用這些詞來指稱 URL 中的元素。 [Internet] URL 和 domain 組成初探 這篇文章有簡單介紹,如果想了解的可以先看過該文章。
Origin 跟 site 到底是什麼?#
先簡單但可能有些許錯誤的解釋 Origin 和 Site,後面再修正。
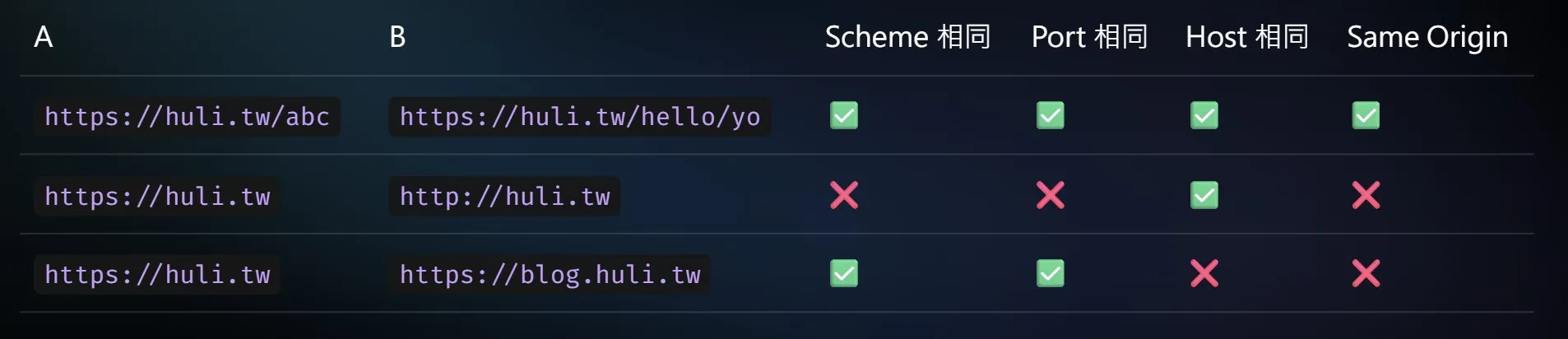
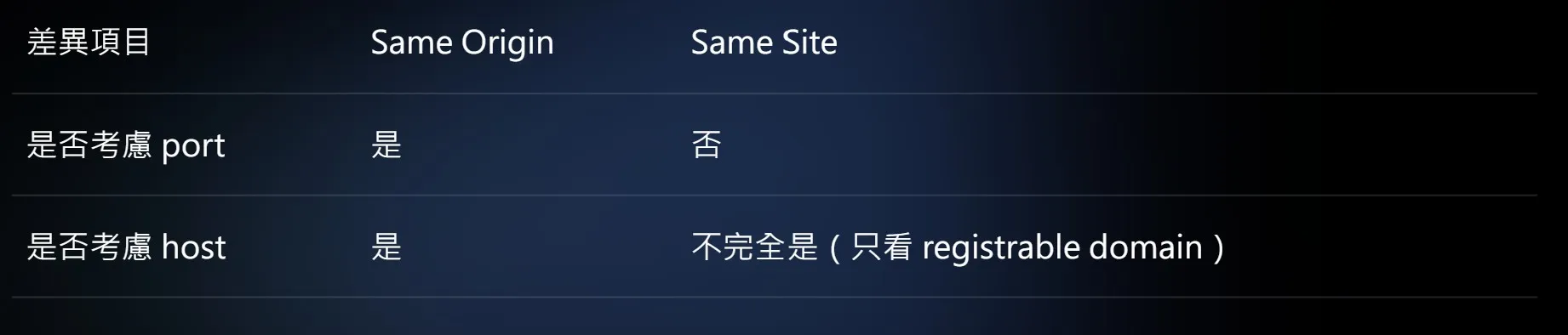
origin 會看三個部分:scheme、port 和 host。若有個 URL 是 https://huli.tw/abc ,它的組成元素如下:
- scheme:
https - port:443(
https的預設 port) - host:
huli.tw
因為 origin 是 scheme + port + host,所以它的 origin 就是 https://huli.tw。
而 same origin 的意思就是兩個 URL 的 origin 要相同(scheme、port、host 完全相同),以下是 same origin 舉例表格:
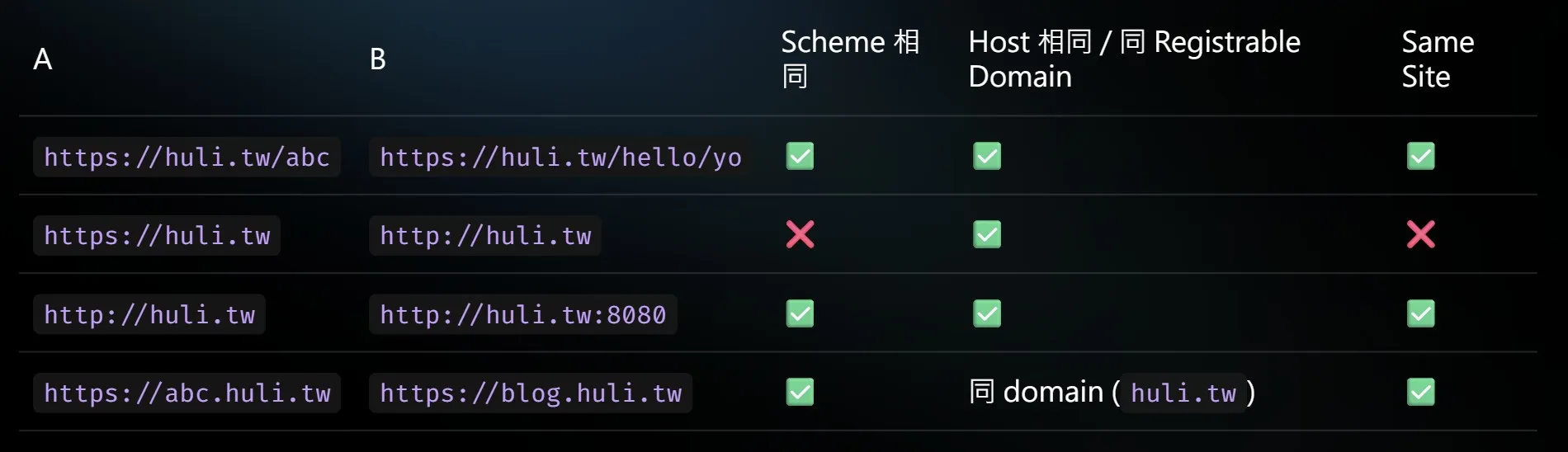
site 會看兩個部分:scheme 和 host,而 same site 就是兩個 URL 的 scheme 和 host 都相同(host 是否相同,會看 registrable domain,後面會再說明)。以下是 same site 舉例表格:
細究 same origin#
HTML spec 中對於origin 的定義是:「Origins are the fundamental currency of the web’s security model. Two actors in the web platform that share an origin are assumed to trust each other and to have the same authority. Actors with differing origins are considered potentially hostile versus each other, and are isolated from each other to varying degrees.」簡單來說,兩網站若有相同 origin,代表可信任彼此;反之就會被隔離且受到限制。
origin 按照 spec 分為兩種:
- An opaque origin:特殊狀況才會出現
例如開本機網頁file:///…發 request 時,origin 會是 opaque origin,而 opaque origin 序列化(serialization)後是 null。 - A tuple origin:常見也是我們主要要關注的 origin
tuple origin 包含以下元素:- scheme (an ASCII string)
- host (a host)
- port (null or a 16-bit unsigned integer)
- domain (null or a domain). Null unless stated otherwise
tuple 型態的 origin 例如(https, huli.tw, null, null),可被序列化為字串https://huli.tw。
而依據 spec,提到 same origin,可分為兩種:
- same origin
- same origin-domain
首先先看 same origin,以下是判斷 A 與 B origin 是否為 same origin 的演算法。
Two origins, A and B, are said to be same origin if the following algorithm returns true:
If A and B are the same opaque origin, then return true.
If A and B are both tuple origins and their schemes, hosts, and port are identical, then return true.
Return false.
可看出在兩種情況下會是 same origin:
- 都是 opaque origin
- 都是 tuple origin,且 scheme、host 和 port 都要相等
舉例來說,https://huli.tw/api 的 origin 是 https://huli.tw,因此 https://huli.tw/* 這類網址才會和它 same origin;又例如https://blog.huli.tw 的 origin 是 https://blog.huli.tw,和 https://huli.tw 不是 same origin,因為 host 不同。
另補充,因 tuple origin 是 tuple 型態,所以「https://huli.tw/api 的 origin 是 https://huli.tw」精確說法其實是「https://huli.tw/api 的 origin 序列化(serialization)過的結果是 https://huli.tw」,若 tuple 和序列化後字串傳達資訊類似,在文章後面都會以序列化後的字串呈現。
看完 spec 的敘述後,same origin 在規範上的定義和前面簡單版解釋差在哪?
- origin 定義多了 opaque origin 這種,且 tuple origin 多了 domain 元素
- 提到 same origin,還多了一種 same origin-domain
細究 same site#
site 在 spec 的定義是:「A site is an opaque origin or a scheme-and-host.」。
site 按照 spec 分為兩種:
- opaque origin
- scheme-and-host
而依據 spec,提到 same site,可分為兩種:
- same site (會看 scheme)
- schemelessly same site (不看 scheme)
首先先看 same site,以下是判斷 A 與 B origin 是否為 same site 的演算法。(補充,2024 年 12 月去查找 spec 時,發現 same site 演算法敘述有更改,但意思應該不變,這裡引用的和書中引用的相同)
Two origins, A and B, are said to be same site if both of the following statements are true:
- A and B are schemelessly same site
A and B are either both opaque origins, or both tuple origins with the same scheme
可看出在兩種情況下會是 same site:
- 都是 opaque origin
- 都是 schemelessly same site,且有相同 scheme
另外,same site 會看 scheme,所以 http 和 https 不是 same site,不過有可能是 schemelessly same site。
關於 same site 和 schemelessly same site 的關係,來稍微了解 same site 定義的發展史。
- same site 一開始是不看 scheme,2016 RFC: Same-site Cookies 中,same site 判斷不包含 scheme
- 2019 年 6 月開始討論是否將 scheme 納入考量,2019 年 9 月在這 PR 中,正式在規格中將 scheme 納入考量,此時將 same site 定義為「會看 scheme」,不看 scheme 的稱為 schemelessly same site
- 2020 年 11 月 Chrome 的文章「Schemeful Same-Site」顯示瀏覽器當時仍把不同 scheme 視為 same site
- 2020 年,Firefox issue [meta] Enable cookie sameSite schemeful的 open 狀態顯示預設還沒把 scheme 納入 same site 考量,若不特別調整,scheme 不同會被視為 same site
- 2021 年 3 月 Chrome 發布 Chrome 89,將 scheme 列入 same site 判斷
回到 same site,前面有提到當「兩個都是 schemelessly same site,且有相同 scheme」時就會是 same site,那如何判斷 schemelessly same site?以下是判斷 A 與 B origin 是否為 schemelessly same site 的演算法。
Two origins, A and B, are said to be schemelessly same site if the following algorithm returns true:
If A and B are the same opaque origin, then return true.
If A and B are both tuple origins, then:
a. Let hostA be A’s host, and let hostB be B’s host.
b. If hostA equals hostB and hostA’s registrable domain is null, then return true.
c. If hostA’s registrable domain equals hostB’s registrable domain and is non-null, then return true.Return false.
可看出在兩種情況下會是 schemelessly same site:
- 都是 opaque origin
- 都是 tuple origin,且 host 相同,而判斷 host 是否相同,會看 registrable domain
看來關鍵是 registrable domain,先來看看 registrable domain 到底是什麼吧!
registrable domain 是什麼#
registrable domain 在 URL spec 的定義是:「A host’s registrable domain is a domain formed by the most specific public suffix, along with the domain label immediately preceding it, if any」(補充,2024 年 12 月去查找 spec 時,發現 registrable domain 的敘述有更改,但意思應該不變,這裡引用的和書中引用的相同)。
以下是一些網站的 registrable domain 舉例:
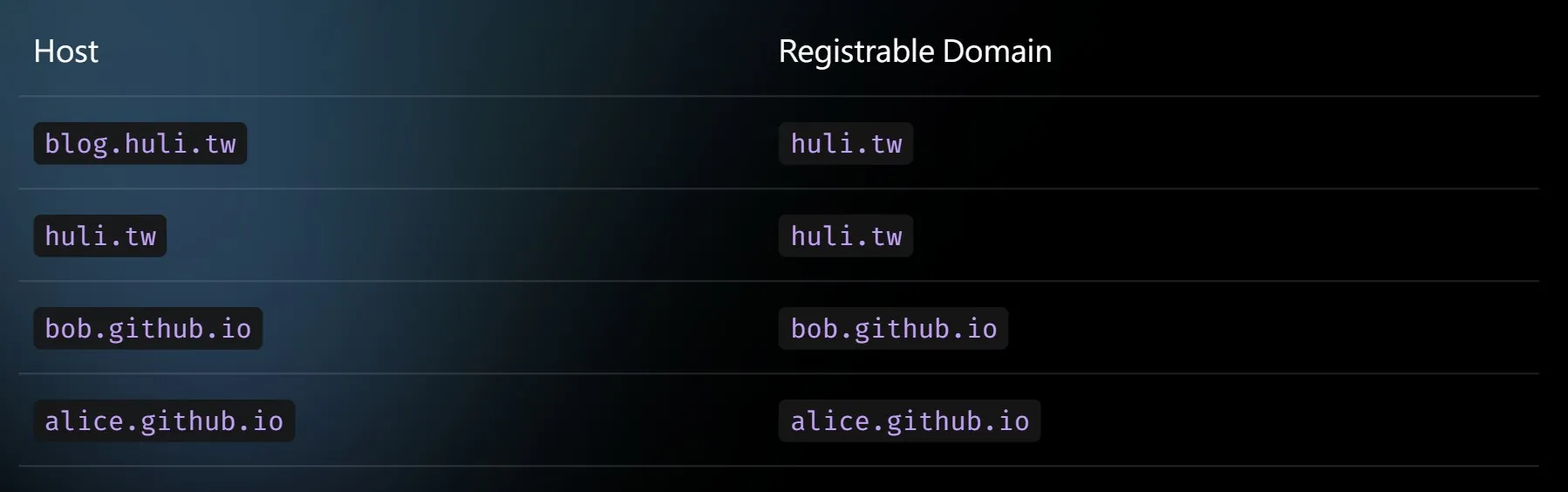
可能會有個困惑想說,為何有的 registrable domain 是 xxx.xx.xx、有的是 xx.xx ?
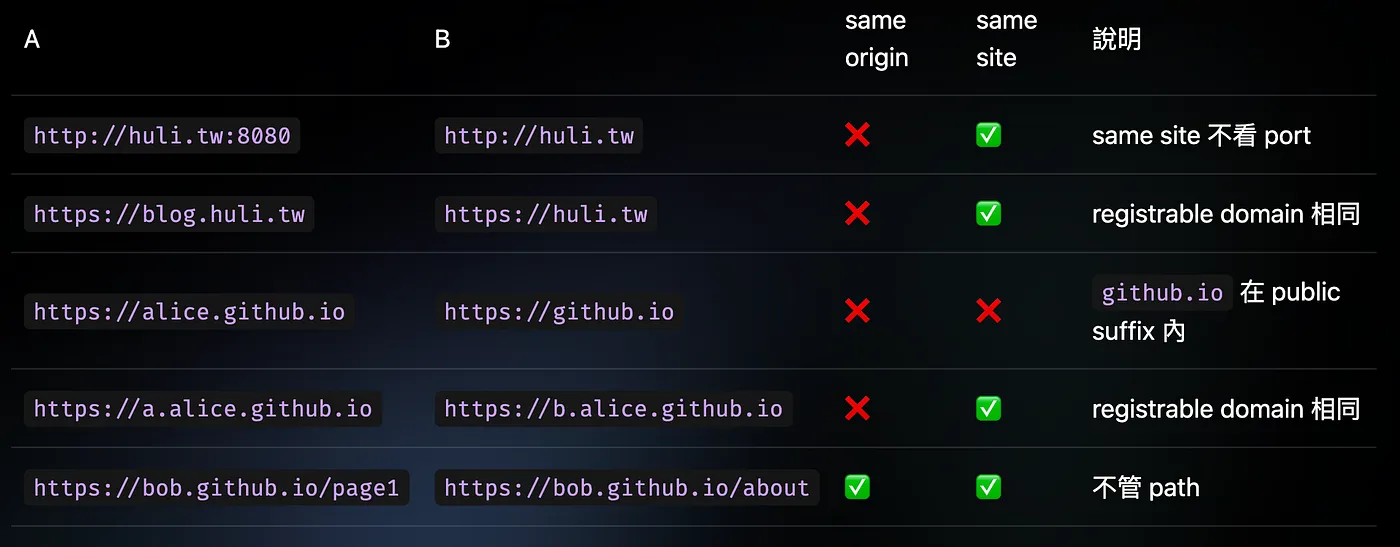
先反過來想,如果沒有 registrable domain 和 public suffix 會怎樣呢? 那huli.tw 跟 blog.huli.tw 會被視為 same site,bob.github.io 跟 alice.github.io 也會被視為 same site,但 bob 和 alice 的網站被視為 same site 有點奇怪,github.io 是 GitHub pages 服務,每個 GitHub 使用者都有自己專屬的 subdomain 可用,而 bob.github.io 和 alice.github.io 屬於不同使用者,希望能被視為兩個獨立網站、互不干擾。此時的解決方式就是 public suffix,public suffix 讓他們可被視為獨立網站。
public suffix 是一個人工維護的清單,有「不想被當作是同個網站的列表」,public suffix 如:github.io、com.tw、s3.amazonaws.com、azurestaticapps.net、herokuapp.com,另外 public suffix 也有名詞稱作 eTLD(effective Top-Level-Domain)。
瀏覽器參考 public suffix 後,才決定 registrable domain 是什麼,因為github.io 存在 public suffix list 內,因此 bob.github.io 的 registrable domain 是 bob.github.io,alice.github.io 的 registrable domain 是 alice.github.io,兩者的 registrable domain 不同,依據 spec 定義,不是 same site,被視為獨立網站。
另附上 spec 中 registrable domain 與 public suffix 舉例表格供參考。
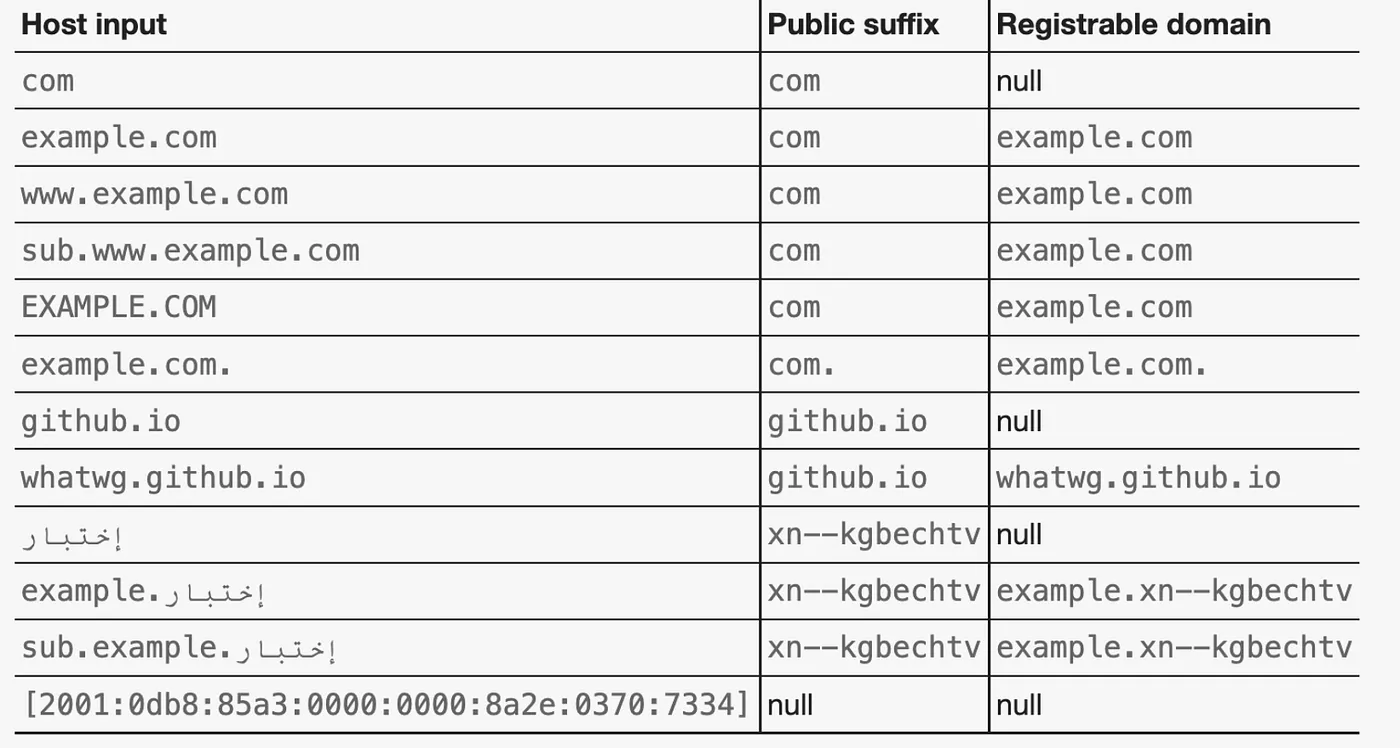
另外整理了簡化版的找出 URL 的 registrable domain 與 public suffix 的步驟:
- 從 URL 的尾端開始,尋找最長的匹配 public suffix,例如對於
whatwg.github.io,匹配的 public suffix 是github.io - 加上 public suffix 左側的一段字串,形成 registrable domain。
以找到的 public suffix,將它的左側的一個 domain label 加入,構成 registrable domain,結構類似:xxx.[public suffix]。另外,registrable domain 又被稱為 eTLD+1,因為是 public suffix 這個 eTLD 加上左側的一個二級域名 label。
例如對於whatwg.github.io,github.io的左側是whatwg,所以 registrable domain 是whatwg.github.io。 - 特殊情況
如果 public suffix 等於整個 host,則沒有更左側的 label,因此 registrable domain 為 null,例如對於github.io,public suffix 是github.io,沒有左側標籤,所以 registrable domain 是 null。
回到 same site,看完 spec 的敘述後,same site 在規範上的定義和前面簡單版解釋差在哪?
host 看起來像在同 parent domain,不代表是 same site,兩個 host 是否 same site,要看 registrable domain,而 registrable domain 要看 public suffix。
舉例來說,bob.github.io 和 alice.github.io 的 registrable domain 不同,不是 same site;而 blog.huli.tw、huli.tw 和test.huli.tw的 registrable domain 相同,是 same site。
Same origin 與 same site#
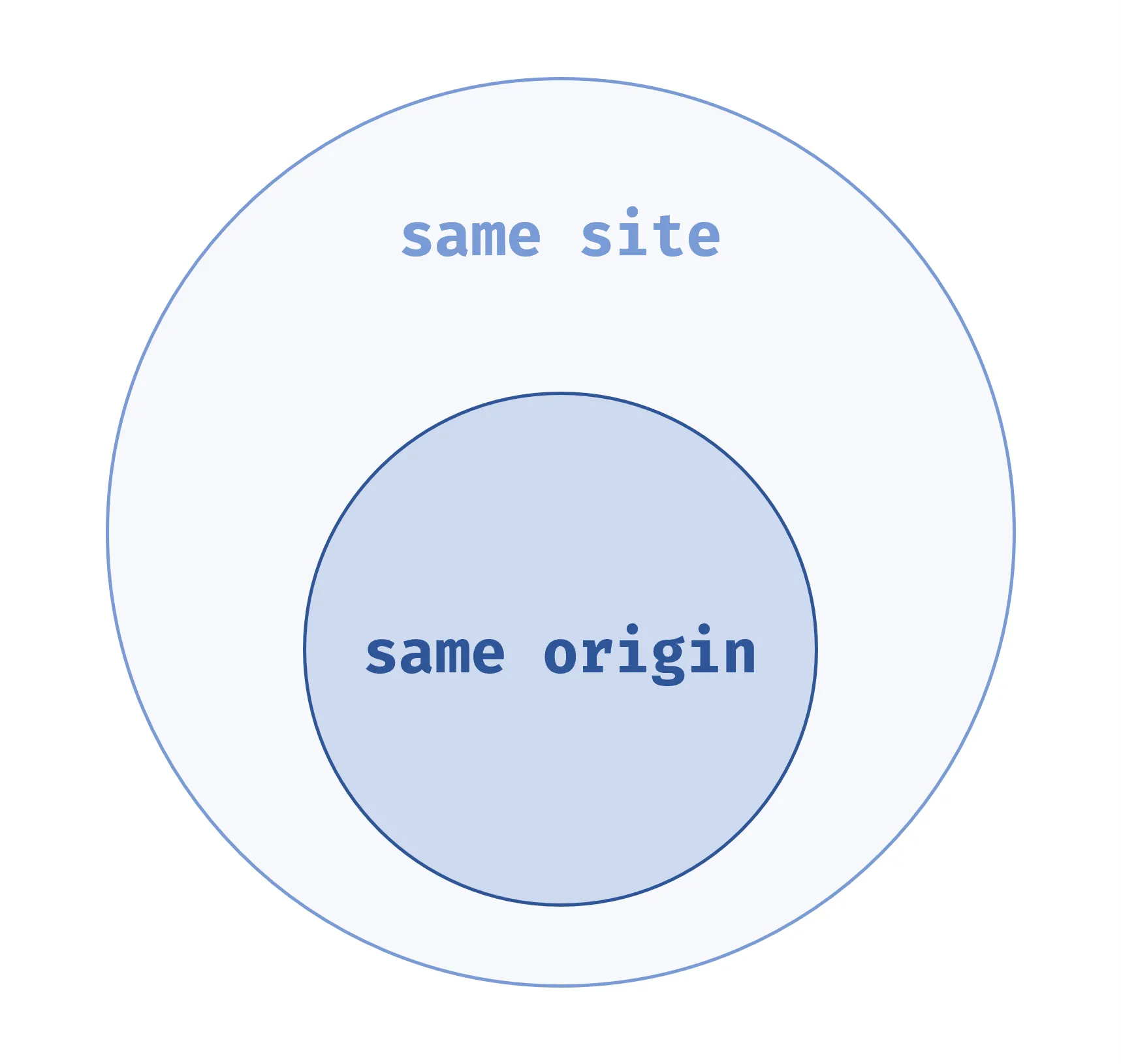
same origin 會看 scheme、port 和 host,而 same site 會看 scheme 和 host(registrable domain)。由此可看出 same origin 比較嚴格,所以兩網站是 same origin,則一定是 same site,兩者關係示意圖如下。
same origin 與 same site 的差別簡單整理表格如下:
另外也附上兩網站是否為 same origin 或 same site 舉例:
神奇的 document.domain#
前面在 origin spec 中還有兩個東西還沒提到:
- tuple origin 定義中包含的 domain 屬性
- same origin-domain
關於 domain 屬性,spec 這樣寫:
Origins can be shared, e.g., among multiple Document objects. Furthermore, origins are generally immutable. Only the domain of a tuple origin can be changed, and only through the document.domain API.
origin 除了 domain 屬性外,其他都不可變(immutable),而domain 屬性可用 document.domain 改變。
關於 document.domain 的說明可參考 7.5.2 Relaxing the same-origin restriction 的這段:
(document.domain) can be set to a value that removes subdomains, to change the origin’s domain to allow pages on other subdomains of the same domain (if they do the same thing) to access each other. This enables pages on different hosts of a domain to synchronously access each other’s DOMs.
直接用個 demo 來說明 document.domain 用途,步驟如下:
- 修改本機
/etc/hosts,讓這兩個網址都連到 local
127.0.0.1 alice.example.com127.0.0.1 bob.example.com修改/etc/hosts 可以將特定域名對應到 127.0.0.1 這個 IP 地址(也就是本機),可參考 localhost 是什麼?。
- 寫一個 HTML server,在
localhost:5555運行
這段程式碼做了三件事:載入 iframe、讀取 iframe 內 DOM 的資料和改變 document.domain。
<!DOCTYPE html><html> <head> <meta charset="utf-8" /> <meta name="viewport" content="width=device-width, initial-scale=1" /> </head> <body> <h1></h1> <h2></h2> <button onclick="load('alice')">load alice iframe</button> <button onclick="load('bob')">load bob iframe</button> <button onclick="access()">access iframe content</button> <button onclick="update()">update domain</button> <br /> <br /> </body> <script> const name = document.domain.replace('.example.com', '') document.querySelector('h1').innerText = name document.querySelector('h2').innerText = Math.random()
function load(name) { const iframe = document.createElement('iframe') iframe.src = 'http://' + name + '.example.com:5555' document.body.appendChild(iframe) }
function access() { const win = document.querySelector('iframe').contentWindow alert('secret:' + win.document.querySelector('h2').innerText) }
function update() { document.domain = 'example.com' } </script></html>- 開啟
http://alice.example.com:5555,點「load bob iframe」載入http://bob.example.com:5555的 iframe,再按 alice 頁面中的「access iframe content」。
此時會看到console 會有錯誤:「Uncaught DOMException: Blocked a frame with origin “http://alice.example.com:5555” from accessing a cross-origin frame.」。原因是要跨越 iframe 存取到 DOM 內容,必須是 same origin,alice 和 bob 雖然是 same site(registrable domain 都是 example.com),但不是 same origin。
- 按下 alice 和 bob 頁面的「update domain」,之後再按 alice 頁面中的「access iframe content」。
此時就可以成功取得 bob 頁面資料。
可看出這裡將 http://alice.example.com:5555 跟 http://bob.example.com:5555 從 cross origin 變成 same origin。same site 居然變成 same origin 了 😮!
上述這個 cross origin 變成 same origin 的魔法看似神奇,但其實有很多限制:
- 只有 same site 網站可以
- 設置時會檢查如下:
The domain setter steps are:
If this’s browsing context is null, then throw a “SecurityError” DOMException.
If this’s active sandboxing flag set has its sandboxed document.domain browsing context flag set, then throw a “SecurityError” DOMException.
Let effectiveDomain be this’s origin’s effective domain.
If effectiveDomain is null, then throw a “SecurityError” DOMException.
If the given value is not a registrable domain suffix of and is not equal to effectiveDomain, then throw a “SecurityError” DOMException.
If the surrounding agent’s agent cluster’s is origin-keyed is true, then return.
Set this’s origin’s domain to the result of parsing the given value.
舉例來說,在 alice.github.io 執行 document.domain = 'github.io' 會出錯:「Uncaught DOMException: Failed to set the ‘domain’ property on ‘Document’: ‘github.io’ is a top-level domain.」,原因是不符合步驟 5 關於 registrable domain suffix 的檢查。
為什麼兩頁面改 document.domain 後,就變成 same origin?
嚴格來說改 document.domain 是讓兩網站變成 same origin-domain,根據 document spec,某些檢查是看 same origin-domain,而非 same origin,節錄如下:
The content document of a navigable container container is the result of running these steps:
If container’s content navigable is null, then return null.
Let document be container’s content navigable’s active document.
If document’s origin and container’s node document’s origin are not same origin-domain, then return null.
Return document.
其中有提到,如果 document 和裡面的 node document(iframe)不是 same origin-domain 那就回傳 null(存取不到);但如果是 same origin-domain,就可存取到 iframe。
看來有個新名詞 same origin-domain 需要認識一下,以下是 spec 中判斷兩網站是否為 same origin-domain 的敘述:
Two origins, A and B, are said to be same origin-domain if the following algorithm returns true:
If A and B are the same opaque origin, then return true.
If A and B are both tuple origins:
(1) If A and B’s schemes are identical, and their domains are identical and non-null, then return true.
(2) Otherwise, if A and B are same origin and their domains are both null, return true.Return false.
可看出在三種情況下會是 same origin-domain:
- A 跟 B 都是 opaque origin
- A 跟 B scheme 和 domain 相同,且 domain 不是 null
- A 跟 B 是 same origin,且 domain 都是 null
(2 和 3 說的 domain 就是指 tuple origin 中的 domain 屬性)
簡單來說,兩網頁都有設置 domain 或都沒有,才有可能是 same origin-domain,若兩網頁都有設 domain,same origin-domain 就不檢查 port。
document.domain 是用來改 tuple origin 中的 domain 屬性,在上面的 demo 範例中,http://alice.example.com:5555 跟 http://bob.example.com:5555 都將自己的 domain 改成 example.com,符合「If A and B’s schemes are identical, and their domains are identical and non-null, then return true.」判斷,因此是 same origin-domain。
document.domain 的淡出及退場#
以 document.domain 放寬 same origin 限制很早就存在,沒移除此方式的原因是為了相容早期行為,早期很多網站都用此方式來存取 same site 但 cross origin 頁面。但 document.domain 可能會有安全性問題,如果某 subdomain 有 XSS 漏洞,就可用這方式擴大影響範圍,實際案例如 An XSS on Facebook via PNGs & Wonky Content Types,攻擊者可從 subdomain 繞到 www.facebook.com 進行 XSS,提升漏洞影響力。
因此 Chrome 針對 document.domain 做了些措施:
- 2022 年發布文章 Chrome will disable modifying document.domain to relax the same-origin policy,指出最快從 Chrome 101 版開始,停止支援更改
document.domain - 2023 年宣布
document.domain的淘汰作業將於 Chrome 115 生效,原本的「以document.domain放寬 same origin 限制」要改用postMessage或Channel Messaging API。若還是想改document.domain,需在 response header 帶上Origin-Agent-Cluster: ?0。
小結#
同源政策是瀏覽器的保護機制,確保只有同源網頁可讀取彼此的資料,而什麼是同源?要先知道 origin 定義,才能判斷是否同源,因此這篇花了許多篇幅解釋和列出 spec 中的定義,了解這些後,才能延伸去認識 CSRF(Cross-site request forgery)和 CORS(Cross-origin resource sharing),因為這些都會和 origin 和 site 有關。
另補充,書中引用的有些 spec 定義和我寫文章當下(2024 年 12月)去查到的 spec 敘述有些微落差,有特別註明在文章中,但個人覺得兩者所表達的意思是相同的,並沒有定義更改的狀況,若有問題也歡迎討論~
Reference:#
- https://url.spec.whatwg.org/
- https://blog.kalan.dev/2021-11-09-url-and-samesite
- https://www.michalspacek.com/origin-site-etld-etld-plus-one-public-suffix-psl-what-are-they
- https://en.wikipedia.org/wiki/Domain_name
- https://html.spec.whatwg.org/multipage/browsers.html
- https://aszx87410.github.io/beyond-xss/ch4/sop-and-site/
如有任何問題歡迎聯絡、不吝指教✍