
前言#
承接上篇 [Security] 細究 Same-origin policy 與 same site,此篇主要敘述的是《Beyond XSS:探索網頁前端資安宇宙》 4–2 ~ 4–3 章節的筆記,若有錯誤歡迎大家回覆告訴我~
4–1 ~ 4–3 章節剛好也是我在讀書會負責導讀的章節,有另外做一份簡報,也可以參考看看簡報,雖然內容大同小異XD,簡報連結點此🔗。
CORS 基本介紹#
同源政策 same-origin policy 意思是瀏覽器會阻止一個網站讀取另一個不同來源網站的資料,但開發時很常遇到一個問題,當前後端在不同 origin 時,前端該如何讀到後端資料?舉例來說前端在 monica.tw、後端在 api.monica.tw,此時解法是 CORS(Cross-Origin Resource Sharing),CORS 是一種可跨來源交換網站資料的機制,開發時很常使用,不過如果設定錯誤就會變成資安漏洞。
為什麼不能跨來源呼叫 API?#
精確來說應該是「為什麼不能用 XMLHttpRequest 或 fetch(也可簡稱為 AJAX)獲取跨來源資料?」
當我們用 img 或 script 請求跨來源資源時並不會遇到問題,但 AJAX 請求卻會被阻擋,例如 <img src="https://another-domain.com/bg.png" /> 可順利拿到圖片。
此時可用反向思考法,當我們已知結果,則此結果一定有原因,可用反證法,若 A 結果是對的,就先假設 A 是錯的,再找出反例發現矛盾,最後證明 A 是對的。因此先假設「擋住跨來源請求」是錯的,再來思考反例,就能發現「擋住跨來源請求」其實是必要的。也可參考 Huli 在這篇文章提到,可以用三個問題來幫助自己理解一項事物:
- 為什麼要有 XXX?
- 沒有 XXX 跟有 XXX 的區別是什麼?
- 所以 XXX 是什麼?
先來思考,如果跨來源請求不會被擋住,會發生什麼事?
我們可以自由串 API,不受任何阻擋,可在自己網域網頁 https://monica.tw/index.html 用 AJAX 拿 https://google.com 資料,非常開心🥳。
可是有些問題,以下來看問題舉例 1:
- 情境:某公司內部網站
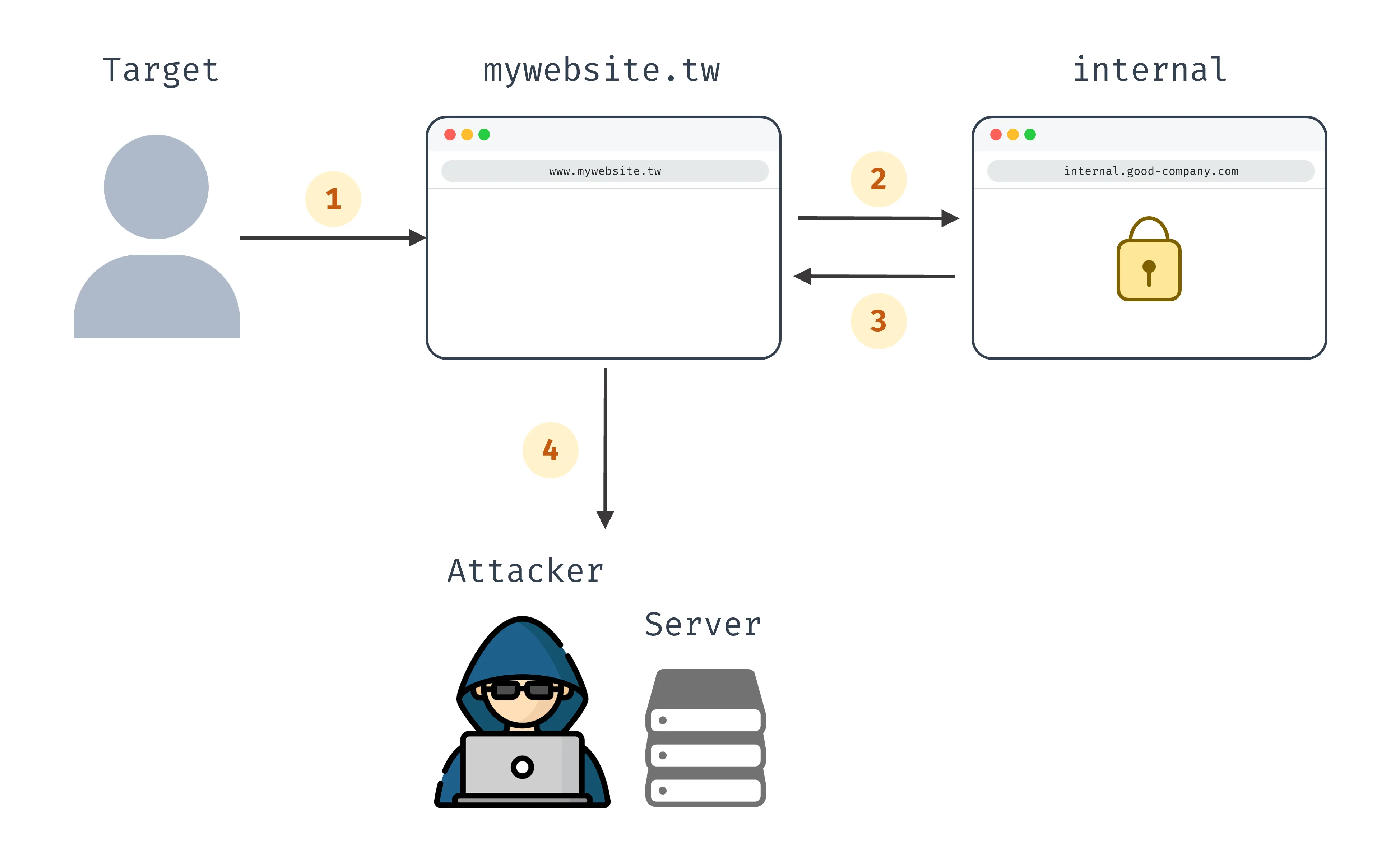
http://internal.good-company.com只有公司員工電腦可連得到(外部無法連) - 問題:在自己的網頁寫一段 AJAX 拿內部網站資料,拿到後再傳回自己 server,就可偷到機密資料,攻擊流程如下:
- 目標(受害者)用公司員工電腦打開惡意網站
- 惡意網站發送 AJAX 請求,取得內部機密網站資料
- 惡意網站拿到機密資料
- 惡意網站將資料回傳給攻擊者 server
也附上示意圖如下。
不過這攻擊有侷限性,因為攻擊者需要先知道內部網站網址,才能攻擊。
問題舉例 2 則是我們平常開發常見的情況,平常開發時很常會在自己電腦開 server,網址如:http://localhost:3000 或 http://localhost:5566。而如果瀏覽器沒阻擋跨來源 API,攻擊者可這樣拿到 localhost server 上的資料:
function sendRequest(url, callback) { const request = new XMLHttpRequest(); request.open('GET', url, true); request.onload = function() { callback(this.response); } request.send();}
// 嘗試針對每一個 port 拿資料,拿到就送回去自己(攻擊者) serverfor (let port = 80; port < 10000; port++) { sendRequest('http://localhost:' + port, data => { // 把資料送回 server })}localhost 上可取得的資料可能是正在開發的公司機密,也可能是可分析網站漏洞的資料,用來做進一步攻擊。
問題舉例 3 則是假設跨來源請求會自動附上 cookie,這樣當使用者瀏覽惡意網站時,惡意網站就可以發 request 到 https://www.facebook.com/messages/t、https://mail.google.com/mail/u/0/,因為會自動帶上使用者 cookie,就能拿到使用者隱私資料。
看完這些問題,再思考一次「為什麼要擋住跨來源的 AJAX?」,答案就是「安全性」,瀏覽器若要拿網站完整內容(可完整讀取),只能用 XMLHttpRequest 或 fetch,若沒限制跨來源 AJAX,就能透過使用者瀏覽器拿到「任意網站」內容,任意網站也包含可能有敏感資訊的網站。
那為什麼不擋圖片、CSS 或 script? 因為用 <img> 引入圖片、用 <link href="..."> 拿 CSS 屬於「網頁資源的一部分」,標籤可拿到的資源有限制,且取回來的資源無法用程式讀取,載入圖片後就只是圖片,只有瀏覽器知道圖片內容,無法用程式讀取代表無法將結果傳到其他地方,比較不會有資料外洩問題。
跨來源 AJAX 是怎麼被擋掉的?#
先簡單敘述個小情境:小明在開發專案時,要使用一個刪除文章的 API,用法是 POST 並帶上文章 id,content type 是 application/x-www-form-urlencoded,另外公司前後端網域不同,且後端沒加 CORS 的 header,小明呼叫刪除文章 API 後,console 跳錯:「request has been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resource」。因此小明認為:「因同源政策限制,AJAX 發不出請求,文章刪不掉」,此說法正確嗎?
小明的故事其實有個很大的誤解,他認為「跨來源請求擋住的是 request」,此想法有誤,我們再看一次錯誤訊息:
request has been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resource
訊息說的是請求的資源沒有 ‘Access-Control-Allow-Origin’ 這 header 存在,代表瀏覽器已經發出 request、拿到 response 才發現沒有 ‘Access-Control-Allow-Origin’ 的 header 存在。因此瀏覽器擋住的不是 request,而是 response(只適用簡單請求),request 已到伺服器,瀏覽器也收到 response,只是瀏覽器不把結果給你。上面小明的故事中,小明的 request 已經到 server,文章已被刪除,只是小明拿不到 response。
有人有「跨來源請求擋住的是 request」的類似誤解,以為發出的請求不會到 server 而向 Chromium 回報 issue,例如 Issue 1122756: Possible to send XHR POST request from different origins — SOP bypass、Issue 1151540: Same-Origin-Policy is bypassed by an XMLHttpRequest Executed within an eval(),這些都被標記不會修,因為這符合規範實作。
可能有人會困惑,脫離瀏覽器就沒 CORS 問題,那攻擊者是不是可以在瀏覽器以外環境向其他機密網站拿資料?在瀏覽器以外環境請求如:用 curl 或 Postman 等工具,就不被 CORS 限制。
但是在瀏覽器發請求與脫離瀏覽器發請求,兩者有根本差異:
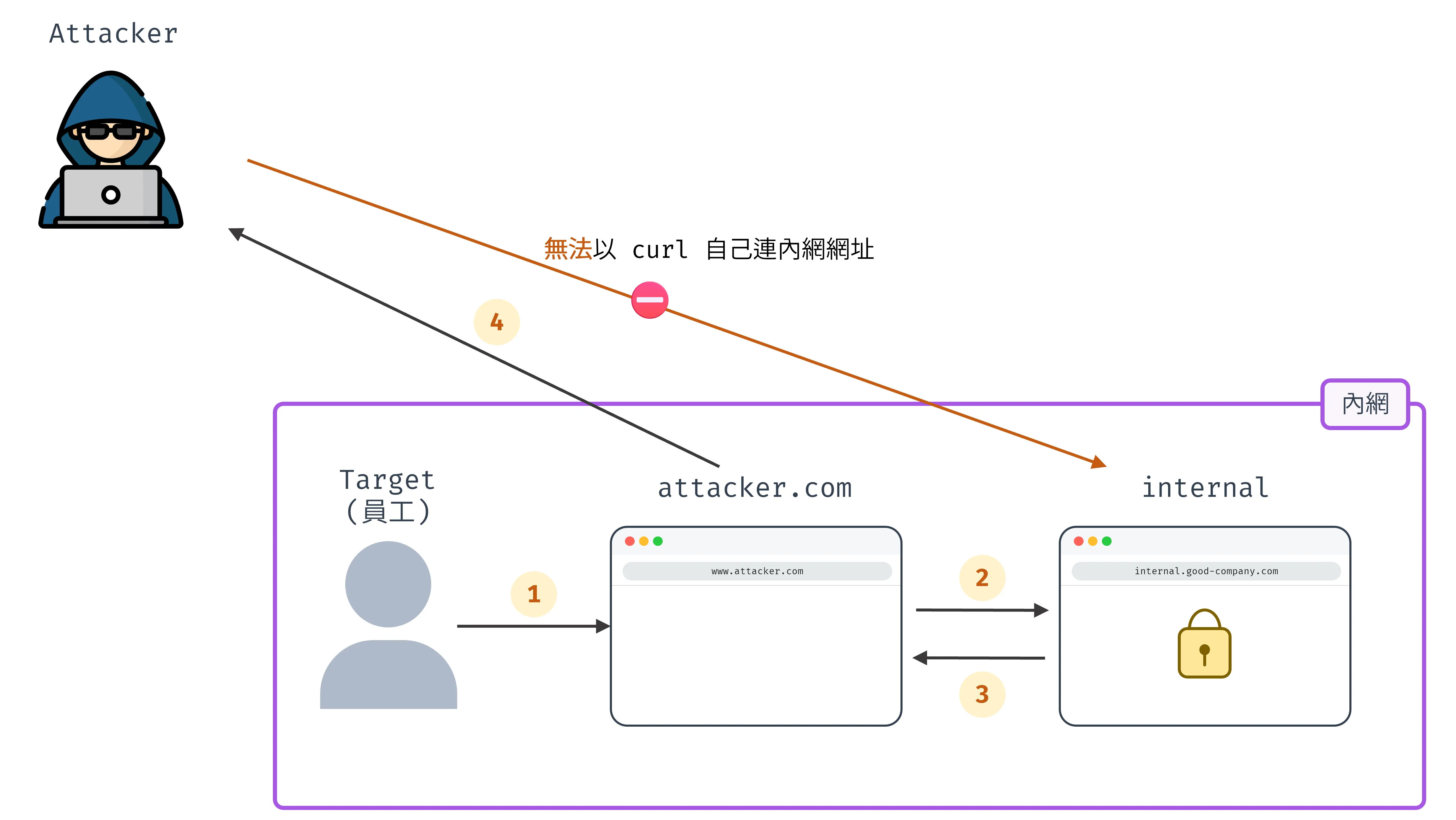
- 脫離瀏覽器發請求:例如在自己電腦用
curl向公司內網http://internal.good-company.com請求,此時只會看到錯誤畫面,因為這不是在公司內網發請求,無權限,且可能連 domain 都無法連到,因為只有內網可以解析此 domain - 在瀏覽器發請求:自己寫個網站,讓內網使用者打開網站,寫好的網站再向內網發請求要資料
兩者最大的差異是在哪個地方(誰的電腦)造訪網站、發出請求,前者是在自己電腦發請求,後者是在其他有連到內網的人電腦發請求。示意圖如下,圖上半是攻擊者自己用 curl連內網網址會失敗,即使沒有 same-origin policy,圖下半是攻擊者寫個惡意網站,讓使用者造訪網站,之後用 AJAX 發 request 到攻擊目標(internal server),拿到資料後再回傳給攻擊者(步驟 4),而如果有 same-origin policy,步驟 4 就不成立,因 JavaScript 拿不到 fetch 結果,不知道 response 內容。
如何設置 CORS?#
設 CORS 的方式就是在伺服器回傳 response 時,在 header 和瀏覽器說:「允許 XXX 存取這請求的 response」。
- 範例 1:
*代表允許任何 origin 讀取這 response
Access-Control-Allow-Origin: *- 範例 2:限制單一來源存取
Access-Control-Allow-Origin: https://blog.huli.tw目前 Access-Control-Allow-Origin 的值不支援多個 origin,只能在伺服器根據 request 動態處理不同 header。
跨來源請求分為「簡單請求」跟「非簡單請求」(ref:Cross-Origin Resource Sharing (CORS)),不論哪種,後端都要給 Access-Control-Allow-Origin header,另外,非簡單請求在發正式請求前會先發一個 preflight request,若 preflight 沒通過就不發正式請求,preflight 請求也要給 Access-Control-Allow-Origin header。簡單來說,簡單請求、非簡單請求的正式請求、非簡單請求的 preflight request 都需要後端給 Access-Control-Allow-Origin header。
若要傳送自定義 header,後端要新增 Access-Control-Allow-Headers 才能通過 preflight,範例如下:
// 假設想帶上自定義 header X-App-Version 紀錄網站版本fetch('http://localhost:3000/form', { method: 'POST', headers: { 'X-App-Version': "v1.1", 'Content-Type': 'application/json' }, body: JSON.stringify(data)}).then(res => res.json()) .then(res => console.log(res))後端回應 preflight 請求時要新增 Access-Control-Allow-Headers:
app.options('/form', (req, res) => { res.header('Access-Control-Allow-Origin', '*') res.header('Access-Control-Allow-Headers', 'X-App-Version, content-type') res.end()})preflight 可視為一種驗證機制,確保後端知道前端送出的 request 符合預期,瀏覽器才會讓前端發出正式 request,因此前面說的「跨來源請求擋的是 response 而不是 request」只適用簡單請求,有 preflight 的非簡單請求,真正的請求會被阻擋。
總結來說,跨來源請求阻擋的是…
- 若是簡單請求,阻擋的是 response 而不是 request
- 若是非簡單請求,阻擋的是真正的 request (因為瀏覽器在 preflight 發現不符合規範後,不會送出正式的 request)
preflight request 的目的#
- 相容性
<form> 是早期網站發請求的方式,但它的功能有限,<form> 的 enctype(表示表單數據的編碼方式)只支援application/x-www-form-urlencoded 和 multipart/form-data,而這些符合簡單請求的定義,但<form> 的 enctype 不支援Content-Type: application/json,而Content-Type: application/json 屬於非簡單請求。因此 <form> 僅能發出簡單請求,任何非簡單請求(例如使用 application/json)都不可能由 <form> 發出。
當新的技術(如 XMLHttpRequest 或 fetch API)被引入時,古老網站沒有預期接收這些新型態的 request,新型態的 request 如:DELETE方法、新的 content-type application/json,但過去時代 <form> 跟 <img> 等元素是唯一能發出 request 的方法,這些元素不會有上述那些新的 request 方式,為了不讓古老網站後端收到預期外 request,就先發 preflight request 確認,若後端沒針對 preflight 處理,瀏覽器不發送真正 request,早期網站不會受到傷害。
2. 安全性
防止瀏覽器在未經確認情況下,直接執行可能會對後端造成未預期影響的操作,舉例來說,用 DELETE 方法呼叫 API 時,若沒有 preflight request,瀏覽器就會直接送出 request,可能對後端造成未預期行為,為確保後端知道待會的 request 合法,才需 preflight request 確認。
跨來源請求與 cookie#
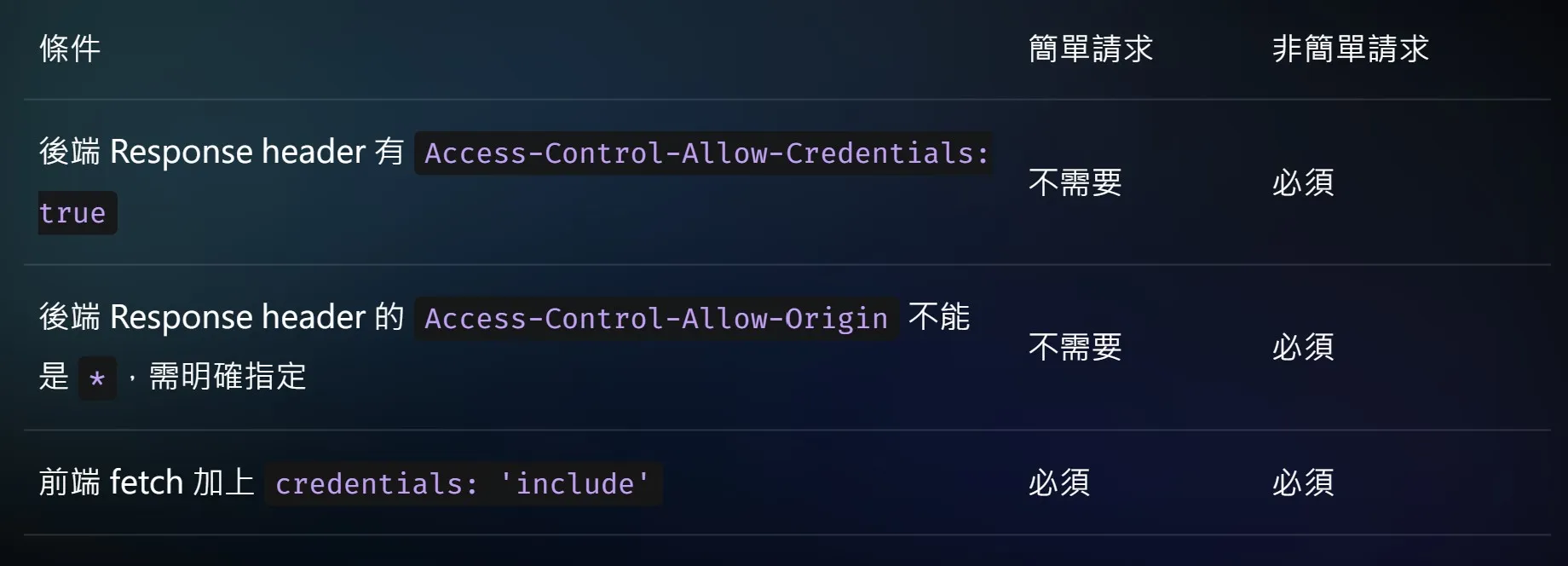
跨來源請求預設不會帶上 cookie,跨來源請求要帶上 cookie,須滿足特定條件,整理如下:
跨來源的安全性問題:CORS misconfiguration#
如果跨來源非簡單請求想帶上 cookie,Access-Control-Allow-Origin 就不能是 *,需指定單一 origin,但可能有多個 origin 都要存取 API,此時就要動態調整 Access-Control-Allow-Origin 裡的 origin。動態調整的設定若有問題,可能會讓攻擊者存取到不該存取的資源。
動態調整 Access-Control-Allow-Origin 裡 origin 的錯誤示範#
錯誤示範 1:直接放入 request header 內的 origin
任何一個 origin 都能通過 CORS,程式碼如下:
app.use((req, res, next) => { res.headers['Access-Control-Allow-Credentials'] = 'true' res.headers['Access-Control-Allow-Origin'] = req.headers['Origin']})可能問題例如攻擊者可以寫一個網站 https://fake-example.com 並讓使用者點擊這網站,攻擊者在網站裡寫這段 script:
// 用 api 去拿使用者資料,並且帶上 cookiefetch('https://api.example.com/me', { credentials: 'include'}) .then(res => res.text()) .then(res => { // 成功拿到使用者資料,可以傳送到自己的 server console.log(res)
// 把使用者導回真正的網站 window.location = 'https://example.com' })因為伺服器會回傳正確 header,認可 https://fake-example.com 是合格 origin,讓 fake-example 這網站也拿到 http://api.example.com/me 的資料,影響範圍視網站 API 而定,可能偷走使用者資料或使用者 token(如果有 API 可以拿 token)。
此攻擊成立的前提有幾個:
- CORS header 給到不該給的 origin
- 網站用 cookie 做身份驗證,且沒設定 SameSite(若有設定 SameSite cookie,攻擊會失效,因 cookie 帶不上去)
- 使用者主動點擊網站並且是登入狀態
錯誤示範 2:用 Regex 判斷 request origin 是否合法
程式碼如下:
app.use((req, res, next) => { res.headers['Access-Control-Allow-Credentials'] = 'true' const origin = req.headers['Origin']
// 偵測是不是 example.com 結尾 if (/example\.com$/.test(origin)) { res.headers['Access-Control-Allow-Origin'] = origin }})可過關的 origin 如:example.com、buy.example.com,但fakeexample.com 也可過關,一樣會造成上面的攻擊問題。
上述這些錯誤 CORS 設置引起的漏洞稱為 CORS misconfiguration,錯誤設置的實際案例例如:
- 2016 年 Jordan Milne 找到的 JetBrain IDE 漏洞(ref)
- 2017 年 James Kettle 在 AppSec EU 研討會分享的比特幣交易所漏洞(ref)
- 2020 年 Asiayo 漏洞(ref)
CORS 正確設置方式#
事先準備允許的 origin 清單,有在清單內的才通過,並設 sameSite cookie,程式碼如下:
const allowOrigins = [ 'https://example.com', 'https://buy.example.com', 'https://social.example.com']app.use((req, res, next) => { res.headers['Access-Control-Allow-Credentials'] = 'true' const origin = req.headers['Origin']
if (allowOrigins.includes(origin)) { res.headers['Access-Control-Allow-Origin'] = origin }})其他各種 COXX 系列 header#
其他以 CO(Cross-Origin) 開頭的 header,也和跨來源資料存取有關
- CORB(Cross-Origin Read Blocking)
- CORP(Cross-Origin Resource Policy)
- COEP(Cross-Origin-Embedder-Policy)
- COOP(Cross-Origin-Opener-Policy)
在那之前,先來看看 Meltdown 與 Spectre~
嚴重的安全漏洞:Meltdown 與 Spectre#
2018 年 1 月 Google 的 Project Zeror 發布一篇 Reading privileged memory with a side-channel 文章,講了三種針對 CPU data cache 的攻擊
- Variant 1: bounds check bypass (CVE-2017–5753)
- Variant 2: branch target injection (CVE-2017–5715)
- Variant 3: rogue data cache load (CVE-2017–5754)
前兩種被稱為 Spectre,第三種稱為 Meltdown,此攻擊十分嚴重,因問題在於 CPU,不容易修復。這漏洞對後續的影響是它加速瀏覽器演進歷程、促進瀏覽器的跨來源資源存取政策。
超級簡化版 Spectre 攻擊解釋#
此為方便理解的簡化版,和原始攻擊有落差,但核心概念相似。
假設一段程式碼(C 語言)如下,這段程式碼做了幾件事:
- 宣告兩陣列 arr1(長度 16)和 arr2(長度 256)
- 函式
run(x)判斷x < array1_size,若符合則執行array2[array1[x]] - 沒超出陣列範圍,理論上沒問題
uint8_t arr1[16] = {1, 2, 3};uint8_t arr2[256];unsigned int array1_size = 16;
void run(size_t x) { if(x < array1_size) { uint8_t y = array2[array1[x]]; }}
size_t x = 1;run(x);程式碼看起來沒什麼問題,但這裡先簡單介紹一下 CPU 機制,CPU 有 Branch Prediction 和 Speculative Execution 的機制,目的是為了增進程式碼執行效率,當 CPU 執行時,若碰到 if,會先預測結果是 true 或 false,若預測結果是 true,就先執行 if 內程式碼,先算出 if 內的結果,實際 if 條件執行完後,若跟預測相同則皆大歡喜,若跟預測不同,就把計算的結果丟掉。在這過程中,Branch Prediction 是「預測」分支的走向;Speculative Execution 是「基於預測結果」執行分支中的程式碼。
這個機制有什麼問題?CPU 丟棄結果後我們也拿不到啊,但問題在於它有留下線索🔺,線索就是預測執行時,運算結果會被放入 CPU cache。那要如何判斷資料是否在 CPU cache 內?可以用存取時間判斷,讀取 CPU cache 內資料較快,所謂的「Side-channel attack」就是攻擊者可利用存取時間(timing attack)來推測 CPU cache 內的資料。
再看一次上面那段程式碼,可能會有什麼問題?當我們跑多次 run(10) 後,branch prediction 預測下次也會滿足條件,提前執行 if 內程式碼,當 x 設為 200 時,預測會執行:uint8_t y = array2[array1[200]];,若 array1[200] 是 38,則執行 y = array2[38],array2[38] 被放入 CPU cache,接著實際執行發現條件不符,丟掉執行結果,此時若用 timing attack 讀取 array2 每個元素並計算時間,會發現 array2[38] 讀取時間最短,回推 array1[200] 內容是 38。
而array1 長度只有 16,array1[200] 是存取到 array1 以外的東西,因此這是存取到其他不該存取到的記憶體,重複這模式可以讀取到其他地方的資料。
上述攻擊原理應用在瀏覽器,就能讀取同一 process 的其他資料,若同一個 process 有其他網站內容,就能讀取其他網站內容,這就是 Spectre 攻擊。一句話解釋就是:「在瀏覽器上,Spectre 讓你有機會讀取到其他網站的資料」。
COXX 系列 header 和 Spectre 的關係是什麼?COXX 主要目的都是為了防止一個網站能讀取到其他網站的資料,避免惡意網站跟目標網站處在同一個 process。
CORB(Cross-Origin Read Blocking)#
阻擋不合理的跨來源資源載入
Spectre 能讀取同一 process 下的資料,因此防禦方式就是不要讓其他網站資料出現在同一 process 底下。
其他網站的資料會如何出現?跨來源存取資源的方式如:
fetch或xhr:已被 CORS 控管,且 response 在 network 相關 process,不是網站本身 process,Spectre 拿不到<img>或<script>:例如<img src="https://bank.com/secret.json">可載入機密資料,但這類資源無法用 JavaScript 讀取。不過 Chrome 下載前不知道它不是圖片(可能副檔名是.json但其實是圖片),因此會先下載,下載後將結果丟進 render process,發現不是圖片才觸發載入錯誤。但這會有問題,因 Spectre 只要在同一 process 就可存取,丟進 render process 還是可以拿到記憶體資料
所以 CORB 機制目的就是:「如果你想讀的資料類型根本不合理,那根本不需要讀到 render process,直接把結果丟掉就好」。
讀的資料類型不合理是什麼意思?例如用 <img> 載入 MIME type 是 application/json 的 JSON 檔、用 <script> 載入 HTML。
CORB 主要保護的資料類型是 HTML、XML 跟 JSON,Chrome 會根據內容探測(sniffing)檔案類型,決定是否套用 CORB,但有誤判可能,若確定伺服器給的 content type 正確,可傳 response header X-Content-Type-Options: nosniff,Chrome 會直接用給定的 content type。
CORB 在 Chrome 已預設使用,會自動阻擋不合理的跨來源資源載入。
CORP(Cross-Origin Resource Policy)#
阻止任何跨來源資源載入,保護網站資源不被其他人載入
CORP 的前身是 From-Origin,Cross-Origin-Resource-Policy (was: From-Origin) #687 對 CORP(From-Origin) 的敘述如下:
Cross-Origin Read Blocking (CORB) automatically protects against Spectre attacks that load cross-origin, cross-type HTML, XML, and JSON resources, and is based on the browser’s ability to distinguish resource types. We think CORB is a good idea. From-Origin would offer servers an opt-in protection beyond CORB.
CORP 使用情境是知道該保護哪些資源,指定這些資源只能被哪些來源載入,例如 server 知道該保護這張圖片,所以設定這張圖片只能由哪些來源網站可載入。
CORP 可填入三種值
same-sitesame-origincross-origin:所有跨來源都可載入
和沒設置差不多,只在 COEP 是require-corp時有差(後面會提到)
主流瀏覽器都已支援 CORP 的使用,可手動傳入,使用方式就是 server 回傳時設 response header Cross-Origin-Resource-Policy,程式碼如下:
app.use((req, res, next) => { res.header('Cross-Origin-Resource-Policy', 'same-origin'); next();});CORP 可視為資源版的 CORS,CORS 是 API 或資料間存取的協議,讓跨來源資料存取需要許可,而 CORP 是資源(如 <img>)間的存取協議,讓任何跨來源資源載入需要許可。原先阻止跨來源資源載入方式是由 server side 自行依據 Origin 或 Referer 等值,動態決定是否回傳資料,現在就可用 CORP 來控制。不過 CORP 的「讓任何跨來源資源載入需要許可」中的任何跨來源不包含 iframe,CORP 對 iframe 無效。
CORP 阻止任何跨來源載入的目的除了安全性,還可以阻止別人載入你的資源,擁有資源者可避免支付對應流量與費用、避免 Clickjacking,也可避免隱私洩漏問題。
Site Isolation#
防止 Spectre 攻擊的方式有兩種:
- 不讓攻擊者有機會執行 Spectre 攻擊
- 就算執行攻擊,也拿不到想要的資訊
如何「不讓攻擊者有機會執行 Spectre 攻擊」?Spectre 攻擊後,瀏覽器做了些調整:
- 降低
performance.now的精準度:Spectre 會透過讀取資料時間差得知哪個資料被放到 cache,降低時間函式的精準度,攻擊者就無法判斷正確的讀取速度 - 停用
SharedArrayBuffer:SharedArrayBuffer可讓 document 的 JavaScript 跟 web worker 共用同一個記憶體,共享資料,停用SharedArrayBuffer讓 JavaScript 和 worker 無法共用記憶體
如何「就算執行攻擊,也拿不到想要的資訊」?
- 不讓惡意網站拿到跨來源網站的資訊,如:CORB、Site Isolation
CORB 已經提過,接下來看看 Site Isolation。
Site Isolation#
Site Isolation 會將不同網站(site)資源放在不同 process,這裡的不同網站定義和 same site 的 site 定義相同,same site 同 process,反之隔離。隔離對象是 process,隔離目的是即使有 Spectre 攻擊也讀不到其他網站的資料。Site Isolation 目前 Chrome 預設啟用,但缺點是使用的記憶體會變多,因為需要更多 process。
cross-origin isolated state#
還有一個更嚴格的隔離方式是 cross-origin isolated state,它將不同網站(origin)資源放在不同 browsing context group,這裡的不同網站和 same origin 的 origin 定義相同,same origin 同 browsing context group,反之隔離。隔離對象是 browsing context group,在設置時要確認自己網站的所有跨來源存取都合法、有權限。
使用 cross-origin isolated state 的方式是在網頁設這兩個 header:
Cross-Origin-Embedder-Policy: require-corpCross-Origin-Opener-Policy: same-origin
接著先來看看 COEP(Cross-Origin-Embedder-Policy)和 COOP(Cross-Origin-Opener-Policy)是什麼吧~
COEP(Cross-Origin-Embedder-Policy)#
確保頁面上所有資源都是合法載入
COEP 可填入的值如下:
unsafe-none:預設值,沒限制require-corp:頁面上所有載入的資源,都必須有 CORP 或 CORS header 存在,且是合法的
舉例來說,若想將網站 a.example.com 變成 cross-rogin isolated state,那就先幫網站加上 header Cross-Origin-Embedder-Policy: require-corp,接著在網頁引入資源 <img src="http://b.example.com/logo.jpg">,而對應提供資源的 b 傳送正確 header 如下程式碼:
app.use((req, res, next) => { res.header('Cross-Origin-Resource-Policy', 'cross-origin');});這裡可看出 CORP 沒設定與設定 cross-origin 的差異,差異在於 CORP 有設 cross-origin 才能通過 COEP require-corp 要求。
COOP(Cross-Origin-Opener-Policy)#
為 same origin 加上更嚴格的 window 共享設定
COOP 目的是規範 window 跟 opener 間的關係,為何要規範? 因為用 window.open 開新網頁時,可操控新網頁 location,新網頁也可用 window.opener 操控原網頁,會有安全性問題。
COOP 可填入的值有這些:
unsafe-none:預設值same-originsame-origin-allow-popupssame-origin-plus-COEP
直接用範例來解釋same-origin 與 same-origin-allow-popups 的意思,假設網頁 A 用 window.open 開啟網頁 B,在遇到以下不同條件時,會有不同的存取限制:

由上可知,互相存取 window 的條件必須是 same-origin,但是否能真的存取,取決於 COOP header。
COOP header 的影響在於,若設定 COOP 但不符規則,window.opener 會變為 null,且無法存取 window.location(若沒設定 COOP,cross origin 也可拿到 location)。
再回到 cross-origin isolated state#
啟用 cross-origin isolated state 要設兩 header:
Cross-Origin-Embedder-Policy: require-corpCross-Origin-Opener-Policy: same-origin
當啟用 cross-origin isolated state,代表頁面上所有跨來源資源你都有權限存取,因為你請求的資源,對方 server 需回應對應 header 來允許。
而進入 cross-origin isolated state 後…
- 使用以下功能的限制較少 (ref:Window: crossOriginIsolated property):
SharedArrayBuffer可用Window.postMessage或MessagePort.postMessage創建或傳遞performance.now可提供更精確結果
- 不能用
document.domain繞過 same-origin policy
最後以一個表格總結 COXX 系列。

Reference:#
- https://aszx87410.github.io/beyond-xss/ch4/cors-intro/
- https://aszx87410.github.io/beyond-xss/ch4/cors-attack/
如有任何問題歡迎聯絡、不吝指教✍