
前言#
承接上篇 [Security] Same-site cookie 與 CSRF 防禦、same-site 攻擊以及 cookie bomb,此篇主要敘述的是《Beyond XSS:探索網頁前端資安宇宙》 5–1~5–3 章節的筆記,若有錯誤歡迎大家回覆告訴我~
Clickjacking 點擊劫持#
clickjacking(點擊劫持)的意思就是使用者原本以為自己點的是 A 網站,但其實點的是 B 網站,使用者的點擊從 A 網站被「劫持」到 B 網站。
clickjacking 影響力例如:
- 舉例 1:如果點的連結背後是轉帳頁面,且帳號、金額都設好,使用者只要一按下連結就會轉錢,那這個 clickjacking 就能造成財物損失
- 舉例 2:使用者乍看畫面是取消訂閱電子報,但其實「確定取消」按鈕下藏的是 FB 按讚按鈕,只要按下「確定取消」就會觸發按讚且無法取消訂閱,這種騙讚攻擊又稱 likejacking
Clickjacking 攻擊原理#
Clickjacking 攻擊原理是將兩網頁重疊,透過 CSS 讓使用者看見 A 網頁,但點的是 B 網頁。技術上實作方式就是先用 iframe 將 B 網頁嵌入,並設透明度 0.001,接著再用 CSS 把自己的內容疊上。
Clickjacking 範例可參考 Huli 的 demo,使用者在頁面中以為自己點的是「確定取消」,實際卻點到「刪除帳號」。
Clickjacking 攻擊手法流程如下:
- 將目標網頁嵌入惡意網頁中(透過 iframe 或其他類似標籤)
- 在惡意網頁上用 CSS 蓋住目標網頁,讓使用者看不見
- 誘導使用者前往惡意網頁並做出操作(輸入或點擊等)
- 觸發目標網頁行為,達成攻擊
Clickjacking 攻擊困難度取決於以下兩者:
- 惡意網站的設計樣貌
- 目標網站原始行為需多少互動
e.g. 點擊按鈕比輸入資訊更容易
不過 Clickjacking 有個攻擊前提,就是使用者在目標網站需要是登入狀態,才能順利對目標網站執行操作。
Clickjacking 的防禦方式#
Clickjacking 利用的原理是將目標網頁嵌入惡意網頁,因此防禦方式就是讓網頁無法被嵌入,無法被嵌入就不會有 Clickjacking 問題。
在這基礎下,Clickjacking 的防禦方式可分兩種:
- 自己用 JavaScript 檢查是否被嵌入
- 以 response header 告訴瀏覽器這網頁是否能被嵌入
1. 🔺🔺 自己用 JavaScript 檢查:Frame busting#
以程式碼檢查如下:
if (top !== self) { top.location = self.location}每個網頁都有自己的 window object,window.self 指向自己的 window;而window.top 指向 top window,可想成整個瀏覽器「分頁」最上層 window。如果是被獨立開啟的網頁,top 和 self 會指向同一 window,而如果是網頁被嵌入 iframe 內,top 會指向使用(包住) iframe 的 window。
舉例來說,localhost 內有 index.html,裡面嵌入兩個 iframe:
<iframe src="https://example.com"></iframe><iframe src="https://monica.tw"></iframe>
若在 iframe 內存取 top,會拿到 localhost/index.html 的 window object,因此可用if (top !== self) 檢查自己是否被放在 iframe 內,如果發現自己在 iframe 內,就改變 top.location 將最上層網頁轉導,以讓使用者察覺。
此方法有個問題,它可被 iframe 的 sandbox 屬性繞過,iframe sandbox 屬性代表這 iframe 功能受限,需明確指定要打開的功能,可指定的值包含:
allow-forms:允許提交表單allow-scripts:允許執行 JSallow-top-navigation:允許改變 top locationallow-popups:允許彈出視窗
若攻擊者這樣載入 iframe,就無法用 JavaScript 檢查 top:
<iframe src="./busting.html" sandbox="allow-forms">沒 allow-scripts,不能執行 JavaScript、不能檢查;但是有allow-forms,可正常提交表單。
針對這點,書中有提及一個進階解法,先隱藏整個網頁,一定要執行 JavaScript 且通過檢查才能開啟,詳細程式碼可參考這裡,不過缺點是如果使用者主動關閉 JavsScript 功能(Disable JavaScript),就都看不到,會影響「關閉 JavsScript 功能」使用者的體驗。
這防禦方式似乎無法完美防禦,但沒關係,現在瀏覽器已支援其他方式來阻擋網頁被嵌入,就是以下要提的「以 response header 告訴瀏覽器這網頁是否能被嵌入」。
2. 🔺 以 response header 告訴瀏覽器這網頁是否能被嵌入:X-Frame-Options#
X-Frame-Options 是一種 HTTP response header,用來決定誰可以把這網頁嵌入,在 2013 年成為完整的 RFC7034。
X-Frame-Options header 可填入的值如下:
DENY- 拒絕任何網頁把這網頁嵌入
- 不行嵌入的 tag 包含:
<iframe>、<frame>、<object>、<applet>、<embed>
SAMEORIGIN- 只有 same-origin 網頁可以
ALLOW-FROM {originName}- 只允許特定 origin 嵌入,其他不行
- 只能放一個值,例如
ALLOW-FROM https://example.com/,若要多個值要像 CORS header,在 server 動態調整輸出
不過 X-Frame-Options header 仍有些問題…
- 問題 1:每個瀏覽器對
SAMEORIGIN和ALLOW-FROM的實作不同,判定可能和想像不一樣
有些瀏覽器只檢查「上一層」跟「最上層」,而非每一層,舉例來說 iframe 可以有無限多層,像是這樣 A 嵌入 B 嵌入 C 嵌入 D:
example.com/A.html--> attacker.com --> example.com/B.html --> example.com/target.html如果是最內層 target.html ,瀏覽器只檢查會檢查上一層(B.html)和最上層(A.html),因此即使設 X-Frame-Options: SAMEORIGIN,檢查仍會過,因為 B.html 和 A.html 是同 origin,可中間其實還夾一層 attacker.com 惡意網頁,仍有風險。
- 問題 2:
ALLOW-FROM支援度不好,主流瀏覽器大都沒支援ALLOW-FROM用法 - 問題 3:MDN 文件已標示 Deprecated,不建議使用,
X-Frame-Options的X代表比較屬於過渡期用途,其用途已被 CSP 取代
3. ✅ 以 CSP 告訴瀏覽器這網頁是否能被嵌入:CSP frame-ancestors#
CSP 指示 frame-ancestors 可達到 X-Frame-Options 的限制效果,限制「哪些網頁可以把我用 iframe 嵌入」,frame-ancestors 設定方式對應 X-Frame-Options如下表格。

稍微比較一下 CSP 的 frame-src 和 frame-ancestors 差異
frame-src- 限制目標:「我這個網頁允許載入哪些來源的 iframe」
- 類似「跟我交往好嗎?」
frame-ancestors- 限制行為和
X-Frame-Options相同 - 限制目標:「哪些網頁可以把我用 iframe 嵌入」
- 類似針對「跟我交往好嗎?」的回答,
frame-ancestors: 'none'代表任何人來告白都說不要
- 限制行為和
舉例 1:index.html 設 frame-src: 'none',則 index.html 內用 <iframe> 載入任何網頁都會被阻擋,不論要載入的網頁設置什麼 CSP 規則
舉例 2:index.html 設 frame-src: https://example.com,且 example.com 設 frame-ancestors: 'none',則 index.html 內用 <iframe> 載入 example.com 會被阻擋,因為 example.com 用 frame-ancestors 拒絕其他人載入它
由上可知,瀏覽器要成功顯示 iframe 的前提是frame-src 和 frame-ancestors 雙方都須同意。
frame-ancestors 支援度
frame-ancestors 是 CSP level2 才支援的規則,2014 年年底逐漸被主流瀏覽器支援。
4. ✅ 瀏覽器已預設的防禦:SameSite=Lax cookie#
SameSite=Lax cookie 也可防禦 Clickjacking 攻擊,因為設置 SameSite=Lax cookie 後,被 iframe 嵌入的網頁不會帶 cookie 給 server,不符合點擊劫持攻擊的前提:「使用者必須是登入狀態」。
same-site cookie 防禦面向多元,可防禦 CSRF,也可防禦點擊劫持攻擊,很讚 👍
Clickjacking 防禦總結#
考量支援度,建議 X-Frame-Options 和 CSP 的 frame-ancestors 一起用,防禦範例如下:
- 網頁不想被 iframe 載入
X-Frame-Options: DENYContent-Security-Policy: frame-ancestors 'none'- 網頁只允許被 same-origin 載入
X-Frame-Options: SAMEORIGINContent-Security-Policy: frame-ancestors 'self'- 用 allow list 指定允許的來源
X-Frame-Options: ALLOW-FROM https://example.com/Content-Security-Policy: frame-ancestors https://example.com/實際案例#
書中有提幾個 Clickjacking 攻擊實際案例,例如:2018 年 hk755a 回報的美國最大的餐廳評論網站 Yelp 漏洞、2015 年 filedescriptor 回報的 Twitter 漏洞、2019 年 eo420 回報的 Twitter 底下 Periscope 漏洞等,就不詳細說明,可再自己參考書中內容。
無法防禦的 clickjacking?#
clickjacking 防禦方式是不要讓別人可嵌入你的網頁,那如果網頁目的就是讓別人嵌入怎麼辦?像是 Facebook widget 「讚」和「分享」的按鈕就是讓人可用 iframe 嵌入,參考 Clickjacking Attack on Facebook: How a Tiny Attribute Can Save the Corporation、Facebook like button click 文章後,FB 的防禦方式是在使用者點按鈕後跳出 popup 再次確認,再次確認的優點是避免 likejacking 風險,缺點則是犧牲使用者體驗,另外也可能會依據網站來源決定是否要再次確認,比較有信譽的網站,可能不會跳這 popup。
Clickjacking 小結#
現代瀏覽器已實作更多安全功能與 Response Header,保護使用者避免惡意攻擊,預設 SameSite Cookie 已減少 Clickjacking 風險,不過仍建議設 X-Frame-Options 和 CSP,多層防護以增加安全性。
結合 MIME sniffing 發起攻擊#
每個 response 幾乎都有 Content-Type 的 response header,Content-Type 目的是告訴瀏覽器這 response 的 MIME type 是什麼,Content-Type 值例如:text/html、application/json。而如果 response 沒有 Content-Type,瀏覽器會根據檔案內容,自己決定這檔案應該要是什麼型態,不過有時即使有 Content-Type header,瀏覽器有時可能還是會當成別的型態,而瀏覽器這種「從檔案內容推測 MIME type」的行為,就稱為 MIME sniffing。
補充:MIME type(ref:MIME type)
現在更準確稱為「媒體類型」(media type),有時被稱「内容類型」(content type),是一種隨文件發送的標識字符串,目的是標示文件類型、描述內容的類型,例如聲音文件可能被標為audio/ogg。
而瀏覽器是如何推測 MIME type 的呢?以 Chrome 為例,我們可參考 Chromium 中,拿來做 MIME sniffing 的程式碼(ref: net/base/mime_sniffer.cc),開頭有一段註解說明它是如何偵測的,節錄如下:
// Detecting mime types is a tricky business because we need to balance// compatibility concerns with security issues. Here is a survey of how other// browsers behave and then a description of how we intend to behave.//// HTML payload, no Content-Type header:// * IE 7: Render as HTML// * Firefox 2: Render as HTML// * Safari 3: Render as HTML// * Opera 9: Render as HTML//// Here the choice seems clear:// => Chrome: Render as HTML//// HTML payload, Content-Type: "text/plain":// * IE 7: Render as HTML// * Firefox 2: Render as text// * Safari 3: Render as text (Note: Safari will Render as HTML if the URL// has an HTML extension)// * Opera 9: Render as text//// Here we choose to follow the majority (and break some compatibility with IE).// Many folks dislike IE's behavior here.// => Chrome: Render as text// We generalize this as follows. If the Content-Type header is text/plain// we won't detect dangerous mime types (those that can execute script).//// HTML payload, Content-Type: "application/octet-stream":// * IE 7: Render as HTML// * Firefox 2: Download as application/octet-stream// * Safari 3: Render as HTML// * Opera 9: Render as HTML//// We follow Firefox.// => Chrome: Download as application/octet-stream// One factor in this decision is that IIS 4 and 5 will send// application/octet-stream for .xhtml files (because they don't recognize// the extension). We did some experiments and it looks like this doesn't occur// very often on the web. We choose the more secure option.另外以下這段,是說明如何才能被 Chromium 視為「HTML payload」。
// Our HTML sniffer differs slightly from Mozilla. For example, Mozilla will// decide that a document that begins "<!DOCTYPE SOAP-ENV:Envelope PUBLIC " is// HTML, but we will not.
#define MAGIC_HTML_TAG(tag) \ MAGIC_STRING("text/html", "<" tag)
static const MagicNumber kSniffableTags[] = { // XML processing directive. Although this is not an HTML mime type, we sniff // for this in the HTML phase because text/xml is just as powerful as HTML and // we want to leverage our white space skipping technology. MAGIC_NUMBER("text/xml", "<?xml"), // Mozilla // DOCTYPEs MAGIC_HTML_TAG("!DOCTYPE html"), // HTML5 spec // Sniffable tags, ordered by how often they occur in sniffable documents. MAGIC_HTML_TAG("script"), // HTML5 spec, Mozilla MAGIC_HTML_TAG("html"), // HTML5 spec, Mozilla MAGIC_HTML_TAG("!--"), MAGIC_HTML_TAG("head"), // HTML5 spec, Mozilla MAGIC_HTML_TAG("iframe"), // Mozilla MAGIC_HTML_TAG("h1"), // Mozilla MAGIC_HTML_TAG("div"), // Mozilla MAGIC_HTML_TAG("font"), // Mozilla MAGIC_HTML_TAG("table"), // Mozilla MAGIC_HTML_TAG("a"), // Mozilla MAGIC_HTML_TAG("style"), // Mozilla MAGIC_HTML_TAG("title"), // Mozilla MAGIC_HTML_TAG("b"), // Mozilla MAGIC_HTML_TAG("body"), // Mozilla MAGIC_HTML_TAG("br"), MAGIC_HTML_TAG("p"), // Mozilla};
// ...
// Returns true and sets result if the content appears to be HTML.// Clears have_enough_content if more data could possibly change the result.static bool SniffForHTML(base::StringPiece content, bool* have_enough_content, std::string* result) { // For HTML, we are willing to consider up to 512 bytes. This may be overly // conservative as IE only considers 256. *have_enough_content &= TruncateStringPiece(512, &content);
// We adopt a strategy similar to that used by Mozilla to sniff HTML tags, // but with some modifications to better match the HTML5 spec. base::StringPiece trimmed = base::TrimWhitespaceASCII(content, base::TRIM_LEADING);
// |trimmed| now starts at first non-whitespace character (or is empty). return CheckForMagicNumbers(trimmed, kSniffableTags, result);}從程式碼可看出,它會檢查 response 移除空白後的字串,看這字串的開頭是否符合列出的 HTML 模式,HTML 模式如:常見的網頁開頭 <!DOCTYPE html、<html、<h1。舉例來說,若 response 移除空白後的字串開頭是 <html,就會被視為 HTML payload。
Chromium 不考慮 URL 上的副檔名或其他因素,只考慮檔案內容,以下範例即使網址是 test.html,在 Chrome 最後呈現仍是純文字。
const express = require('express');const app = express();
app.get('/test.html', (req, res) => { res.write('abcde<h1>test</h1>') res.end()});
app.listen(5555, () => { console.log('Server is running on port 5555');});但如果是 Firefox,test.html 最後呈現會是 HTML,可推測 Firefox 做 MIME sniffing 時,會參考網址列的副檔名。
利用 MIME sniffing 進行攻擊#
若 response 沒設 content-type,且內容可自己操控,我們就可利用 MIME sniffing 讓瀏覽器把檔案當成網頁顯示,舉例來說,假設有個上傳圖片功能只檢查副檔名、沒檢查內容,那我們就可以上傳 a.png 檔案,內容是 <script>alert(1)</script>,此時若伺服器輸出圖片時沒有自動加 content-type,就變成 XSS 漏洞。
現在伺服器基本都會自動加 content-type,還可能發生上述這類攻擊嗎?
有,MIME sniffing 可結合別的問題一起利用。舉個 Apache HTTP Server 的例子,Apache HTTP Server 是個常被使用的伺服器,而如果 Apache HTTP Server 收到的檔案檔名裡只有 .,就不會輸出 Content-Type,像是 a.png 會自動從副檔名偵測 MIME type 並輸出 image/png,但如果是..png 就不會輸出 Content-Type。且根據 Apache HTTP Server 說法,此為預期行為,不會修復。
這時如果後端用 Apache HTTP Server 處理下載檔案功能,攻擊者就可上傳看似是合法圖片的 ..png,但瀏覽器打開後卻呈現為網頁,變成 XSS 漏洞。
可以執行 JavaScript 的 content type#
可執行 JavaScript 的檔案例如:
- HTML 檔案
- XML
- SVG
- 其他可執行 JavaScript 的完整 Content-Type 清單可參考 Content-Type that can be used for XSS
因 SVG 也可執行 JavaScript,因此若允許使用者在網站上傳 SVG 圖片,等於開放上傳 HTML,使用者可藉機執行 JavaScript。2022 年 febin 回報的 Mantis Bug Tracker 漏洞就和上傳 SVG 檔案並藉機執行惡意程式碼有關。
可以當成 script 載入的 content type#
以下 script URL 的 content type 要是什麼,瀏覽器才會當作 script 載入?
<script src="URL"></script>直接以下表的舉例來說明,哪些可以哪些不行:
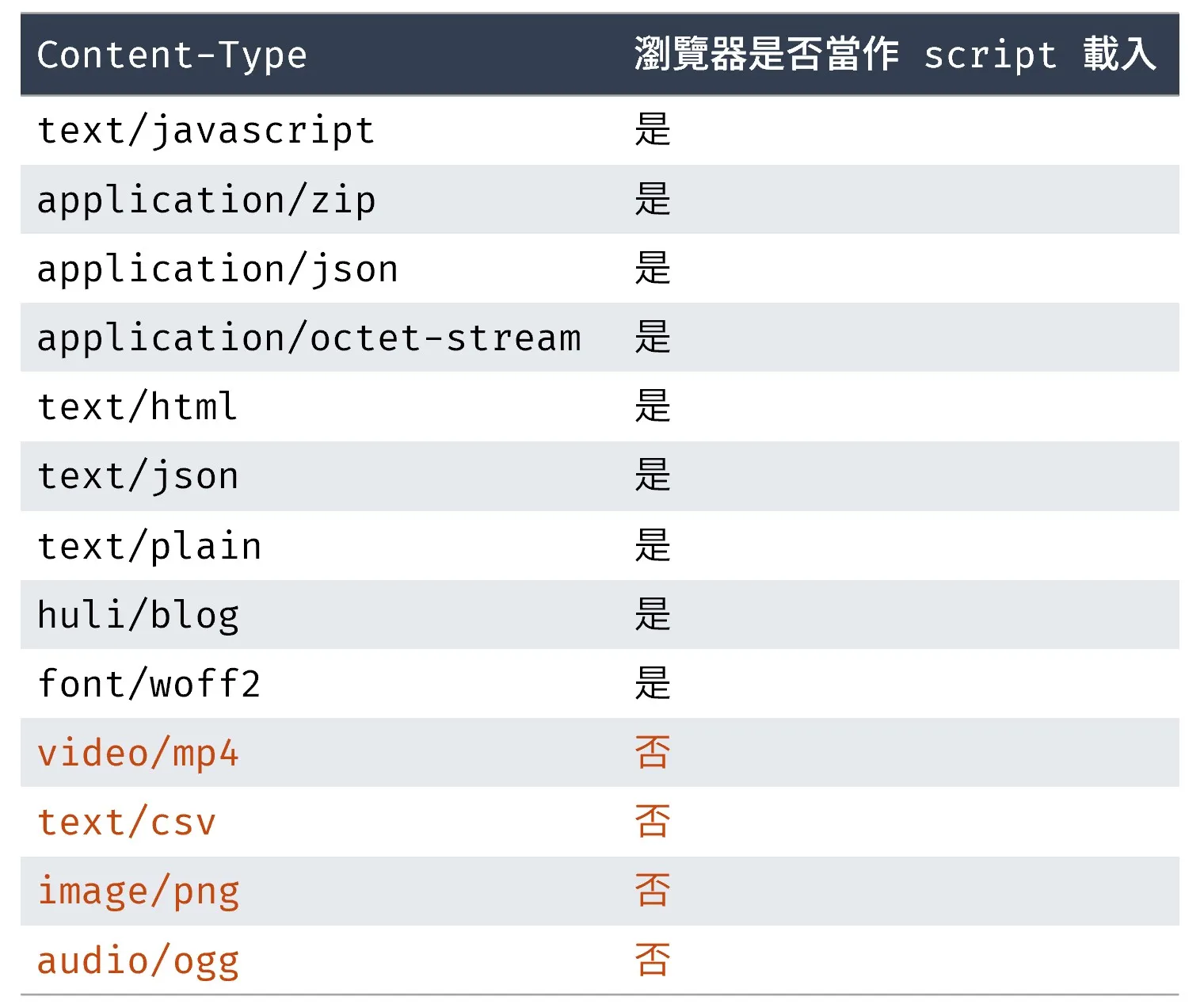
如果是不能作為 script 載入的,瀏覽器會跳錯。例如 script 若載入 image/png 時,會跳錯:「Refused to execute script from ‘http://localhost:5555/js’ because its MIME type (‘image/png’) is not executable.」
在 Chromium 的原始碼中,有列出合法的 JavaScript MIME type:
// Support every script type mentioned in the spec, as it notes that "User// agents must recognize all JavaScript MIME types." See// https://html.spec.whatwg.org/#javascript-mime-type.const char* const kSupportedJavascriptTypes[] = { "application/ecmascript", "application/javascript", "application/x-ecmascript", "application/x-javascript", "text/ecmascript", "text/javascript", "text/javascript1.0", "text/javascript1.1", "text/javascript1.2", "text/javascript1.3", "text/javascript1.4", "text/javascript1.5", "text/jscript", "text/livescript", "text/x-ecmascript", "text/x-javascript",};根據規格,可以/不可以被作為 script 載入的 content type 如下。
- 不可以:只有以下四種不行被作為 script 載入
audio/*image/*video/*text/csv
- 可以:JavaScript MIME type 和上述四種以外的,其他都可以
如果覺得允許作為 script 載入的 content type 類型太廣泛,想要只讓 JavaScript MIME types 載入,其他都不允許,可在 response 新增 header:X-Content-Type-Options: nosniff,加 X-Content-Type-Options: nosniff 後,用 script 載入上述表格列的 content type 都不行,會跳錯。而 style 也是,加上X-Content-Type-Options: nosniff 後,用 style 載入時,只有 text/css 會被認可,其他會跳錯。
維持寬鬆的 Content-Type sniff 會增加資安風險,攻擊舉例如下:
- 攻擊情境:某網站有 XSS,網站有上傳檔案功能,接受圖片、影片、CSV 以外的檔案
- 攻擊限制:網站 CSP 是
script-src 'self';,無法引入外部 script、無法用 inline script - 攻擊方式:上傳圖片時上傳一個內容是 JavaScript 程式碼的 ZIP 壓縮檔,接著可用
<script src="/uploads/files/my.zip"></script>引入 script,繞過 CSP - 攻擊原理:只要不是上述那四種 MIME types,其他都可作為 script 載入,可藉機達成攻擊
因此多數網站加上 X-Content-Type-Options: nosniff 的原因是為了防止上述「利用上傳檔案執行 JavaScript」的攻擊。
Content type 檢查的繞過#
讓使用者上傳檔案的功能,需檢查 content type 才能避免資安風險,檢查方式可分:
- 檢查前綴,如
type.startsWith('image/png') - 檢查後綴,如
type.endsWith('image/png') - 檢查是否包含,如
type.includes('image/png') - 完全比對,如
type === 'image/png'
而 content type 規格允許多變化:
- 單純形式可以:
application/json - 加上參數也可以:
application/json; foo=bar
因此 「檢查後綴」和「檢查是否包含」有可繞過的方法,Grafana 的 CSRF 漏洞 原因就是使用第 3 種檢查,檢查是否包含 application/json,是的話就當作 json 處理,但是攻擊者可用帶上參數的 text/plain; application/json 繞過檢查,真正的 content type 是前面那段,後面是參數。同理可用同方式繞過針對後綴的檢查(e.g. 後綴參數放合法 content type,但其實前面真正 content type 是別的)。
「檢查前綴」的繞過方法可看 2024 年 Flatt Security 發表針對 content type 的研究 XSS using dirty Content-Type in cloud era,有提到不同規格對 content type 解析邏輯不同,例如 fetch 標準中,content type 允許用逗號分隔,而 application/json, text/html 最後解析出的 content type 是 text/html,因此檢查前綴會有不一致情形,只看前面認定是 JSON,但後面的 , text/html 讓它被解析為 HTML。
所以檢查 content type 最好、最安全的方式是完全比對,例如一定要是 application/json,多字或少字都不行。
前端供應鏈攻擊:從上游攻擊下游#
供應鏈攻擊(supply chain attack) 意思是針對上游漏洞的攻擊,只要汙染上游,下游也會一併被汙染。這個上游對前端來說,可能是前端 npm 套件、第三方 script 等。使用第三方資源,伴隨一定的風險。
cdnjs#
前端應用經常需使用第三方 library (e.g. jQuery、Bootstrap),而使用第三方 library 的方式可分幾種:
- 用 webpack 自己打包
- 自己下載一份檔案
- 找現成 CDN 載入
例如:cdnjs、jQuery 官方的 code.jquery.com 和 Bootstrap 使用的 jsDelivr
舉例來說,如果現在我的網站要用 jQuery,用 <script> 載入 jQuery 函式庫的來源可能是…
- 自己的網站
- jsDelivr:https://cdn.jsdelivr.net/npm/jquery@3.6.0/dist/jquery.min.js
- cdnjs:https://cdnjs.cloudflare.com/ajax/libs/jquery/3.6.0/jquery.min.js
- jQuery 官方:https://code.jquery.com/jquery-3.6.0.min.js
如果選 jQuery 官方,就會這樣引入:<script src="https://code.jquery.com/jquery-3.6.0.min.js"></script>,引入後就可使用 jQuery 功能。
選擇 CDN 載入的優點有幾個:
- 省心力,用別人的最快
- 預算考量,放別人網站可節省自己網站流量花費跟負荷
- 速度考量
如果載入的函式庫來自 CDN,下載的速度可能會比較快,因為 CDN 在不同國家可能都有節點,若主機在美國而函式庫放自己網站,台灣使用者要要連到美國伺服器,但如果主機在美國而函式庫用 CDN,台灣使用者可連到台灣節點,能節省延遲
選擇 CDN 載入的缺點如下:
- 依賴 CDN 的穩定度:若 CDN 掛了,網站可能會跟著一起掛或連線緩。真實案例例如 cdnjs 背後公司 Cloudflare 曾有意外並影響許多網站
- 資安風險:若 CDN 被駭客入侵,引入的函式庫被植入惡意程式碼,網站就會跟著一起被入侵,此攻擊稱為「供應鏈攻擊」,入侵上游連帶影響下游
解析 cdnjs 的 RCE 漏洞#
2021 年 7 月 資安研究員 @ryotkak 發布文章指出 Cloudflare 的 Remote code execution(RCE)漏洞,攻擊者若利用 RCE 漏洞,可控制整個 cdnjs 服務。
補充:Remote code execution
Remote code execution(簡稱 RCE)是指可讓攻擊者執行任意程式碼的漏洞。
漏洞的形成#
- Cloudflare 與 cdnjs 相關的程式碼中,有個自動更新功能有漏洞:造成一個「可以寫檔案」的漏洞
npm 自動更新功能流程是這樣:先自動抓 npm 上打包好的 package 檔案,這個檔案格式是壓縮檔 .tgz,解壓縮後,稍微處理檔案,並複製到合適的位置。
但這個解壓縮流程可能有漏洞,在 Go 語言裡面,若用 archive/tar 來解壓縮,檔名沒經過處理可能會像../../../../../tmp/temp 這樣,因此一個攻擊可能會是這樣:
- 情境:若一段複製程式碼的流程是…
- 用目的地 + 檔名拼湊出目標位置,建立新檔案
- 讀取原檔案,寫入新檔案。例如目的地是
/packages/test,檔名是abc.js,最後會在/packages/test/abc.js產生新檔案
- 問題:若目的地是
/packages/test,用 Goarchive/tar解壓縮得到檔名是../../../tmp/abc.js,最後會在/package/test/../../../tmp/abc.js產生新檔案,也就是在/tmp/abc.js下寫入檔案
這攻擊影響力在於它可寫入檔案到任何有權限的地方,若覆蓋到重要檔案,會讓系統掛掉。
cdnjs 自動更新功能的程式碼有類似的解壓縮漏洞,攻擊方式是利用解壓縮流程的漏洞覆蓋原本就會定時自動執行的檔案,達成 RCE。
2. Git repo 自動更新流程中的複製檔案功能,若遇到 symbolic link 檔案可能有問題:造成一個「可以讀檔案」的漏洞
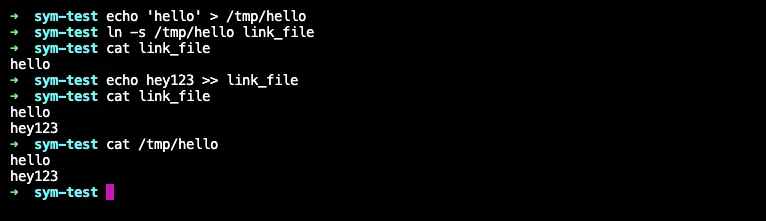
先背景說明一下什麼是 symbolic link,其概念類似 Windows 上的「捷徑」,捷徑只是個連結,會連到真正的目標。在類 Unix 系統中,可用 ln -s 目標檔案 捷徑名稱 建立 symbolic link。範例如下:
(1) 建立一個檔案,內容是 hello,位置是 /tmp/hello
(2) 在當前目錄下建立一個 symbolic link,指向剛建立好的 hello 檔案:ln -s /tmp/hello link_file
(3) 若印出 link_file 內容,會出現 hello,因為這等於印出 /tmp/hello 的內容
(4) 若對 link_file 寫入資料,實際上是對 /tmp/hello 寫入
回到 Git repo,以下是 Git repo 自動更新功能中的複製檔案程式碼:
func MoveFile(sourcePath, destPath string) error { inputFile, err := os.Open(sourcePath) if err != nil { return fmt.Errorf("Couldn't open source file: %s", err) } // 開啟新檔案 outputFile, err := os.Create(destPath) if err != nil { inputFile.Close() return fmt.Errorf("Couldn't open dest file: %s", err) } defer outputFile.Close() // 把舊檔案複製過去新檔案 _, err = io.Copy(outputFile, inputFile) inputFile.Close() if err != nil { return fmt.Errorf("Writing to output file failed: %s", err) } // The copy was successful, so now delete the original file err = os.Remove(sourcePath) if err != nil { return fmt.Errorf("Failed removing original file: %s", err) } return nil}複製邏輯看起來沒什麼問題,但如果是複製的檔案是 symbolic link,程式不是「複製一個 symbolic link」,而是「複製指向的檔案內容」,舉例來說以 Node.js 複製檔案(link_file 是一個 symbolic link,指向 /tmp/hello)會這樣寫:
node -e 'require("fs").copyFileSync("link_file", "test.txt")'執行後,目錄下會多一個 test.txt 檔案,內容是 /tmp/hello 檔案內容,由此可見程式執行複製檔案時,會複製指向的檔案內容,而非複製 symbolic link。
複製的檔案是「複製指向的檔案內容」有何問題?
上述複製檔案程式碼中,若有個檔案是指向 /etc/passwd 的 symbolic link,複製完後就會產出內容是 /etc/passwd 的檔案,可能的攻擊方法像這樣:
- 在 Git 檔案內加一個 symbolic link,稱作
test.js,讓它指向/etc/passwd - 被 cdnjs 複製後,會產生一個
test.js檔案,且裡面是/etc/passwd的內容,可造成任意檔案讀取(Arbitrary File Read)漏洞
結合兩漏洞(寫檔案+讀檔案)的攻擊#
攻擊方式
- 建一個 Git 倉庫然後發佈新版本,等 cdnjs 自動更新
- 自動更新時觸發檔案讀取的漏洞
- 在 cdnjs 發布的 JS 上可看到讀取的檔案內容
攻擊影響力
若讀取的檔案是 /proc/self/environ ,內有環境變數、GitHub api key,而這個 GitHub api key 對 cdnjs 下的 repo 有寫入權限,可用這把 key 去改 cdnjs 或 cdnjs 網站的程式碼,進而控制整個服務。
由這案例可知,即使是大公司,也有被入侵的風險。Cloudflare 後續的事件處理可參考 Cloudflare’s Handling of an RCE Vulnerability in cdnjs,他們重寫架構,將解壓縮的部分放到 Docker sandbox 內。
身為前端工程師,該如何防禦供應鏈攻擊?#
有個 integrity 屬性可用來告訴瀏覽器,如果檔案被竄改過,就不要載入。這樣即使 cdnjs 被入侵、jQuery 被篡改,網站也不會載入。使用方式是當我們在 cdnjs 要引入 library 時,可選擇複製「URL 🔗」或「script tag </>」。

若選擇「script tag </>」,會得到以下:
<script src="https://cdnjs.cloudflare.com/ajax/libs/react/19.0.0/cjs/react.production.min.js" integrity="sha512-nU+Ng6Lv1UThPJ9vMtDIEfW0pNWLZQsRwh0cCl3WJHjReVWnxLEWSY/esU9/v1iBsfoe0Y71xwOcpoVrhNcU4Q==" crossorigin="anonymous" referrerpolicy="no-referrer"></script>crossorigin="anonymous"意思是以 CORS 方式送出 request,避免 cookie 隨請求送出,而 integrity 意思是瀏覽器會用 integrity 來確認要載入的資源是否符合提供的 hash 值(ref:Subresource Integrity),如果不符合,代表檔案被竄改過,就不會載入。
integrity 屬性的優點是即使 cdnjs 被入侵,瀏覽器也會因為 hash 不合而不載入資源,限制則是只能防止「已經引入的 script」被竄改,如果在駭客竄改檔案後才複製 script,就沒有用了。
完全避免 CDN 供應鏈攻擊的方式是不要用第三方提供的服務,把 libray 放自己的 CDN 上,將第三方的風險變成自己服務的風險。不過仍可能有其他供應鏈攻擊的風險,若從 npm 下載函式庫,當 npm 被入侵時,npm 上游仍會影響到你的服務,此時防禦方式可以是 build time 時使用靜態掃描服務或公司內部架 npm registry,不直接與外面 npm 同步。
供應鏈攻擊小結#
引用第三方服務時,為了安全性,應該…
- 確認對方網站值得信任
- 加上 integrity 屬性
- 注意 CSP 設定(對 cdnjs 網站,若 CSP 只設置 domain,已有可行的繞過手法)
Reference:#
- https://aszx87410.github.io/beyond-xss/ch5/clickjacking/
- https://aszx87410.github.io/beyond-xss/ch5/mime-sniffing/
- https://aszx87410.github.io/beyond-xss/ch5/supply-chain-attack/
如有任何問題歡迎聯絡、不吝指教✍️