
前言#
承接上篇 [Security] 瀏覽器安全模型與 XSS 初探,此篇主要敘述的是《Beyond XSS:探索網頁前端資安宇宙》 2–1 ~ 2–3 章節的筆記,若有錯誤歡迎大家回覆告訴我~
XSS 的第一道防線:Sanitization#
在前篇文章中,我們認識了 XSS 的幾種攻擊與注入方式,也大略提及該如何防禦 XSS,今天這篇會比較完整的介紹 XSS 的多道防禦方式~
首先,前篇文章曾提過,我們可用編碼(encode)或跳脫(escape)的方式防禦 XSS,將使用者的輸入編碼,不被解析為原本意思,例如編碼 <>"' 這幾個符號。而還有另一種方式是消毒/淨化(sanitization),意思是將使用者輸入中有危害的部分清除,其中負責處理淨化的程式碼稱為「sanitizer」。
encode 和 sanitization 聽起來相似,但其實不太一樣,差異在於「最後是否還會顯示這些文字」:
- encode:把輸入中的特定字元編碼,最後還是會以純文字顯示
- sanitization:把不符規則的全刪掉,最後不會被顯示
接著就來看看該如何處理使用者的輸入吧~
處理使用者輸入 — 最基本的手段:編碼#
為何 XSS 會成立?因為認知差異,工程師預期使用者輸入的都是純文字,但瀏覽器卻將這些輸入解析為 HTML 程式碼一部分,這個認知差異造就了攻擊發生。因此要讓 XSS 攻擊不成立,就是讓使用者輸入變成該有的樣子,讓認知差異不要發生。
如何讓使用者輸入變成該有的樣子?就是預設用安全方式撰寫,同時留意那些不安全的(如:<a href> 問題)。以前端來說,用 JavaScript 將使用者輸入放到畫面時,使用 innerText 或 textContent,輸入就會被解讀為純文字,安全 ✅;而前端框架 React 或 Vue 已內建類似功能,這些框架在 render 時就預設所有東西都是純文字,若開發者需要 render HTML 再用特殊方式渲染(如 dangerouslySetInnerHTML 或是v-html)。以後端來說,PHP 可用 htmlspecialchars 函式來編碼字元,若是用模板引擎(template engine)來輸出,像是 Laravel 用的 Blade 模板引擎中,{{ $text }} 就是代表編碼過的,{!! $text !!} 就是代表沒編碼過的。
但某些時候還是需要不安全的輸出方式,因為這段文字原本就是 HTML,希望能以 HTML 的方式渲染呈現,這時就需要做 sanitize。
處理使用者輸入 — 處理 HTML#
一句話總結就是:
用別人已經做好的 library,不要自己做。
建議直接使用現成框架或程式語言內的相關功能,或使用專門處理 sanitization 的 library。
會強調要專門處理 sanitization 的 library,是因為如果不是專門處理 sanitization 的,可能處理時仍會有問題。例如 Python 的 BeautifulSoup library 可用來解析網頁,但不是專門做 sanitization,因此可能會有些問題,例如以下範例:
from bs4 import BeautifulSouphtml = """ <div> test <!--><script>alert(1)</script>--> </div>"""tree = BeautifulSoup(html, "html.parser")for element in tree.find_all(): print(f"name: {element.name}") print(f"attrs: {element.attrs}")BeautifulSoup 程式碼的輸出如下,它將這段 HTML 解析為一個 div 元素:
name: divattrs: {}但如果是由瀏覽器解析上述那段 HTML,則會跳出 alert 視窗,代表 BeautifulSoup 的檢查已被繞過。
為何檢查會被繞過?因瀏覽器和 BeautifulSoup 對這段 HTML 的解析不同:
<!--><script>alert(1)</script>-->對 BeautifulSoup 來說,它會將 HTML 解析為一個用 <!--跟 ->包住的註解;但對瀏覽器來說,根據 HTML5 的 spec,<!-->是合法註解,因此會將其視為註解加上<script>標籤、再加上文字->。

另外補充,如果將 BeautifulSoup parser 換成 html5lib 就可正確解析為 <script>。
那專門處理 sanitization 的 library 有什麼呢?接著來看一個專門處理 sanitization 的 library 吧~
DOMPurify:專門用來做 sanitization 的 library#
DOMPurify 是一個來自德國資安公司 Cure53 開源的套件,專門做 HTML sanitization,使用方式如下:
const clean = DOMPurify.sanitize(html);DOMPurify 的 sanitize 方法做了什麼?它做了…
- 清除危險標籤及屬性
- 防禦其他攻擊,如:DOM clobbering
- 拿掉屬性中的 event handler
- 清掉
javascript:偽協議
DOMPurify 有些預設允許的標籤,這些標籤在預設情況下不會被清除,預設允許的例如:<h1>、<p>、<div> 、<span>,<script> 標籤也是預設允許的。
若希望允許更多標籤,可調整 DOMPurify 設定來允許更多標籤和屬性:
const config = { ADD_TAGS: ['iframe'], ADD_ATTR: ['src'],};
let html = '<div><iframe src=javascript:alert(1)></iframe></div>'console.log(DOMPurify.sanitize(html, config))// <div><iframe></iframe></div>
html = '<div><iframe src=https://example.com></iframe></div>'console.log(DOMPurify.sanitize(html, config))// <div><iframe src="https://example.com"></iframe></div>因上述範例的 config 只允許 iframe 的 src 屬性,沒有允許 javascript:,所以 javascript:會被清除。
而如果要允許可能會造成 XSS 的屬性或標籤,DOMPurify 也不會阻止:
const config = { ADD_TAGS: ['script'], ADD_ATTR: ['onclick'],};
html = 'abc<script>alert(1)<\/script><button onclick=alert(2)>click me</button>'console.log(DOMPurify.sanitize(html, config))// abc<script>alert(1)</script><button onclick="alert(2)">click me</button>我有試著在 React 中使用 DOMPurify,來處理上篇文章所說的,在 href放 javascript: 偽協議的問題,程式碼如下,我用 isValidAttribute 來判定連結是否合法:
import { useState } from "react";import DOMPurify from "dompurify";
export default function PurifyInput() { const [href, setHref] = useState("");
const handleInputChange = (event) => { const inputVal = event.target.value; const isValidHref = DOMPurify.isValidAttribute("a", "href", inputVal); if (isValidHref) { setHref(inputVal); } };
return ( <div> <h3>Input with DOMPurify</h3> <input type="text" placeholder="請輸入網址" onChange={handleInputChange} /> <br /> <a href={href}>click me</a> </div> );}完整 demo 可見連結,有比較沒使用 DOMPurify 和有使用 DOMPurify 的兩種輸入框。
另外也可參考官方提供的 demo,可試試看 DOMPurify 會如何處理 HTML。
正確的函式庫,錯誤的使用方式#
如同上面所說,當我們在 DOMPurify 設定可能會造成 XSS 的屬性或標籤時,即使用了 DOMPurify 這種專門 sanitization 的 library,還是有可能出錯,因此正確函式庫需搭配官方文件的正確使用方式。
相關漏洞案例例如 HackMD 在 2019 年被發現的過濾內容的漏洞,HackMD 用 js-xss 套件過濾內容,但是在設定檔的設定方式讓攻擊者有辦法繞過並執行攻擊,詳細說明可見 A Wormable XSS on HackMD!。
另外一個誤用套件的漏洞案例是,網站在後端已經用 DOMPurify 過濾好內容,但是在前端 render 時有再利用函式去處理過濾好的內容,而當這個函式不夠安全、有可控制的地方,攻擊者就可利用這函式的處理過程來製造 XSS、達成攻擊。這種「手動調整已過濾好內容」的行為稱為 desanitization,應盡量避免 desanitization,若要調整內容應在 sanitization 前調整,並確保 sanitization 是資料處理的最後一關。
由上可知,即使使用了套件,有兩種方式還是能讓安全的東西變得不安全:
- ⛔ 使用錯誤的設定
- ⛔ 過濾以後再修改內容
XSS 的第二道防線:CSP#
會發生資安問題有幾個原因:
- 你不知道這樣做會出事
- 你忘記這樣做會出事
- 你知道這樣做會出事,但因為各種原因決定不管它
如果是第一種,不知道會有漏洞、不知道可能會被攻擊,該怎麼防禦?
這時就需要 XSS 第二道防線,CSP。
自動防禦機制:Content Security Policy#
Content Security Policy(CSP) 中文稱為「內容安全政策」,開發者可透過 CSP 為網頁訂規範,和瀏覽器說網頁只允許符合這規則的內容,不符合的都擋掉。
幫網頁加上 CSP 的方式有:
- 以 HTTP response header
Content-Security-Policy來設定- 實務上較常用,有些規則只能用此方式設定
- 以
<meta>標籤設定- 因較容易示範,文章會以這種方式說明
先來看個 CSP 範例:
<!DOCTYPE html><html><head> <meta http-equiv="Content-Security-Policy" content="script-src 'none'"></head><body> <script>alert(1)</script> CSP test</body></html>我們在 <meta http-equiv="Content-Security-Policy" content="script-src 'none'">這行中設定 CSP 為script-src 'none',意思是這網頁不允許任何 任何 JavaScript 的執行,不論是 script 標籤、event handler 還是 javascript: 偽協議都會阻擋執行,也因此上方 body 中的 script 不會執行,且網頁 console 會印出錯誤訊息:「Refused to execute inline script because it violates the following Content Security Policy directive: “script-src ‘none’”…」。
由此可看出,即使攻擊者順利植入 XSS payload,我們也可透過第二道防線 CSP 來阻擋它的執行或載入。
CSP 的規則#
CSP 的定義方式是指示(directive)+ 規則,例如上面範例,就是指示 script-src 加上規則 'none' 。
補充:
script-src不能解釋為 script 標籤的 src,這裡的 script 是一般「腳本」的意思。不專指 script 標籤、不專指 src 屬性。
指示的種類#
指示的種類會隨時間變化或增加,以下列出常見的:
default-src:填入預設規則
假設某些指示沒特別設定規則,就會用default-src的內容,但也有些指示沒設置也不會使用default-src內容,如:base-uri、form-action,哪些會用default-src可看 The default-src Directive。script-src:管理 JavaScriptstyle-src:管理 CSSfont-src:管理字體img-src:管理圖片connect-src:管理連線(fetch、XMLHttpRequest 以及 WebSocket 等等)media-src:管理 video 跟 audio 等等frame-src:管理 frame 以及 iframe 等等base-uri:管理<base>的使用form-action:管理表單的 actionframe-ancestors:管理頁面可以被誰嵌入navigate-to:管理頁面可以跳轉到的地方
較新,目前瀏覽器還沒支援report-uri:可設定 CSP,但不會真的阻擋,只會在有載入違反 CSP 規則的資源時,傳送報告到指定的 URL(目前已被 MDN 官方文件標示為 Deprecated,建議改用report-to,文章後面會再提到)
規則的種類#
根據指示不同,可使用的規則也不同,常見規則如:
*:允許除了data:、blob:和filesystem:以外所有的 URL
例如可設定script-src *,但這通常有設跟沒設差不多(JavaScript 都不會被阻擋)'none':什麼都不允許script-src 'none':無法執行任何 JavaScript'self':只允許 same-origin 的資源https:允許所有 HTTPS 的資源example.com:允許特定 domain(HTTP 跟 HTTPS 皆可)https://example.com:允許特定 origin(只允許 HTTPS)
有些規則可疊加,例如可以這樣寫:
script-src 'self' cdn.example.com www.google-analytics.com \*.facebook.net因 script 放在 same-origin,需要 self,有些 script 放在 CDN,因此需要 cdn.example.com,有用 Google Analytics、Facebook SDK,所以要允許
www.google-analytics.com、*.facebook.net 來源的載入。
完整的 CSP 範例可以這樣寫:
default-src 'none'; script-src 'self' cdn.example.com www.google-analytics.com *.facebook.net; img-src *;CSP 的目的是用來告訴瀏覽器哪些資源允許、不允許載入,同時降低 XSS 攻擊影響力,即使攻擊者找到注入點,也不一定能執行 JavaScript。
script-src 的規則#
設置 CSP 時,預設禁止:
- inline script,inline script 包含:
<script>標籤內直接放程式碼(script 應該要用<script src>從外部引入)- 寫在 HTML 裡的 event handler (如:
onclick) javascript:偽協議
- eval(把字串當程式碼執行)
- eval 如:
setTimeout、setInterval、Function可把字串當程式碼執行,例如setTimeout('alert(1)')
- eval 如:
而 script-src 除了可規範載入資源的 URL,還可用其他規則:
'unsafe-inline':讓 inline script 可以執行'unsafe-eval':讓 eval 可以執行'nonce-xxx':讓加上隨機字串 xxx 的 script 可以執行
例如後端隨機產一字串a3b4zsa17c,帶上nonce=a3b4zsa17c的 script 標籤就可執行。
<!-- 允許 --><script nonce=a3b4zsa17c> alert(1)</script>
<!-- 不允許 --><script> alert(1)</script>'sha256-xxx...':允許特定 hash 的 inline script
例如alert拿去 sha256 後會拿到 binary 值,base64 後是bhHHL3z2vDgxUt0W3dWQOrprscmda2Y5pLsLg4GF,當設定sha256-bhHHL3z2vDgxUt0W3dWQOrprscmda2Y5pLsLg4GF+pI=就只有內容剛好是alert(1)的 script 可被載入。
<!DOCTYPE html><html><head> <meta http-equiv="Content-Security-Policy" content="script-src 'sha256-bhHHL3z2vDgxUt0W3dWQOrprscmda2Y5pLsLg4GF+pI='"></head><body> <!-- 允許 --> <script>alert(1)</script>
<!-- 不允許 --> <script>alert(0)</script>
<!-- 多一個空格也不允許,因為 hash 值不同 --> <script> alert(1)</script></body></html>'strict-dynamic':符合規則的 script 可載入其他 script,不受 CSP 限制
例如以下範例,只有nonce-rjg103rj1298e是允許的 script,但<script nonce=rjg103rj1298e>裡新增的 script 不受限制,可動態加入其他來源的新 script。
<!DOCTYPE html><html><head> <meta http-equiv="Content-Security-Policy" content="script-src 'nonce-rjg103rj1298e' 'strict-dynamic'"></head><body> <script nonce=rjg103rj1298e> const element = document.createElement('script') element.src = 'https://example.com' document.body.appendChild(element) </script></body></html>怎麼決定 CSP 規則要有哪些?#
- Step 1:先設置
default-src 'self',先預設 same-origin 資源都可載入。 - Step 2:處理 script 的規則
建議不要使用'unsafe-inline'跟'unsafe-eval',因這樣幾乎等於沒防範,隨意插入 tag<svg onload=alert(1)>就可執行程式碼。如果仍需載入 Google Analytics 這類的 inline-script,可幫那一段 script 加上 nonce、或是算出那段 script 的 hash 並加上sha256-xxx的規則,透過允許特定 inline script 的方式來載入,而非使用權限全開的'unsafe-inline'。可參考 Google 官方提出的說明「使用代碼管理工具搭配內容安全政策」。 - Step 3:可搭配使用 CSP Evaluator 來偵測 CSP 的設定是否安全。下圖是貼上 CSP 設定後,會列出可能有危險的地方。
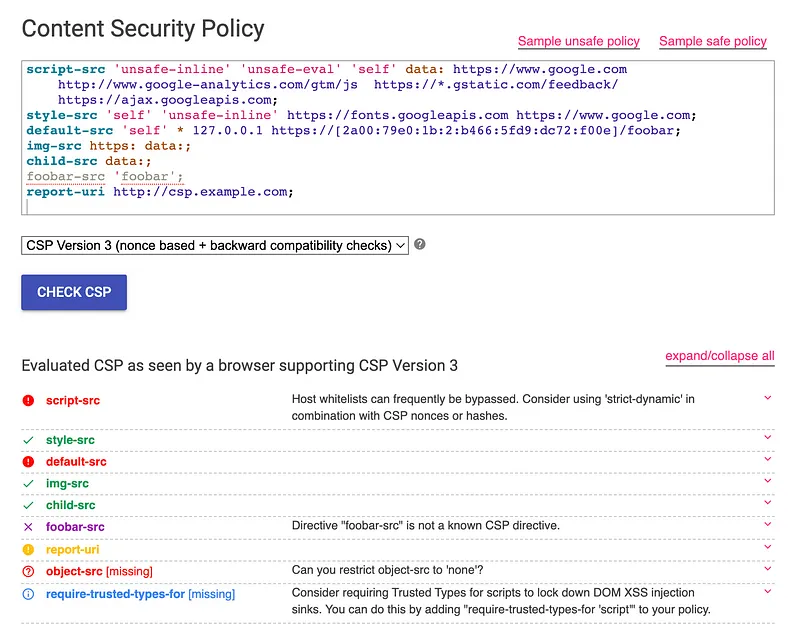
- (可選)Step 4:可參考別的網站的 CSP 設定,例如去看 GitHub 首頁的 CSP 或是 Facebook 的 CSP 設定,像 GitHub CSP 的
script-src只設定github.githubassets.com;,算蠻安全的。(Github 和 Facebook 的 CSP 規則在這裡 Huli 有貼出來 )
Content-Security-Policy-Report-Only#
文章前面有提到「report-uri」這個指示,這指示的意思是,我們可設定 CSP,但實際上不會真的阻擋資源的載入或執行,只會在有載入違反 CSP 規則的資源時,傳送報告到指定的 URL,如此可避免影響正常資源的載入。不過 report-uri 目前已被 MDN 官方文件標示為 Deprecated,建議改用 report-to,但官方文件也有說目前 report-to 還沒被廣泛支援,建議是 report-uri 和 report-to 兩個都一起寫:
Content-Security-Policy: …; report-uri https://endpoint.example.com; report-to endpoint_name而 Content-Security-Policy-Report-Only 和 report-uri、report-to 用意類似,只會在有載入違反 CSP 規則的資源時,傳送報告到指定的 URL。
在設定 CSP 規則時,有時會擔心設定的 CSP 規則阻擋應用程式正常的運作,讓使用者無法正常使用,這時就可用 Content-Security-Policy-Report-Only 的方式,先觀察網站會有哪些違反 CSP 的狀況,再來檢視 CSP 設定是否 OK,避免真的影響使用者的正常操作。
蠻推薦大家設定 CSP 規則的,有設定就多一道防線,即使 XSS 問題發生,也可透過 CSP 阻擋 XSS payload 被執行,如果害怕規則沒設好,也可先從 report only 的 CSP 開始,觀察可能會違反的情況,同時調整 CSP 規則,避免影響正常功能,有開始總是比沒開始好💪
XSS 的第三道防線:降低影響範圍#
前面提了 XSS 的兩道防線:
- 第一道防線:編碼或消毒使用者的輸入,避免使用者輸入惡意內容
- 第二道防線:設置 CSP,即使攻擊者能順利植入 HTML,也無法執行 JavaScript 或載入其他資源
接著要談第三道防線:假設 XSS 必然發生,那我們能做什麼降低損害?
為何要假設 XSS 必然發生?因為我們無法保證每一層防禦都百分之百可靠。例如,第三方函式庫可能存在 0-day 漏洞、第三方函式庫原始碼中可能夾帶惡意程式碼、甚至 CSP 規則也可能被成功繞過。也因此才會有第三道防線,假設真的防不住,XSS 真的發生,我們能做什麼來降低損害。
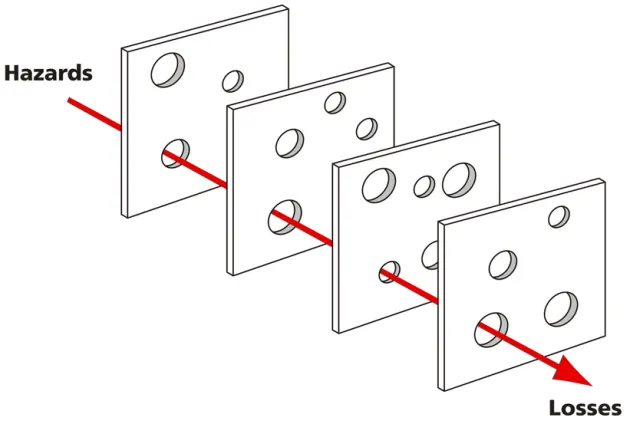
這個多層防護的概念讓我想到之前研究所讀到的「瑞士奶酪理論 (Swiss Cheese Model)」,意思是意外事件的發生源於多層防護中剛好所有漏洞重疊,就像多片起司疊在一起。通常每片起司的孔洞位置不同,光線無法穿透;然而在少見情況下,當孔洞連成一直線時,光線得以穿過。因此,增加防護層數(疊更多起司片)或減少每層的漏洞(縮小孔洞、降低孔洞數)可降低漏洞被穿透的機率,進一步提升整體安全性。(ref )
補充:0-day
零日漏洞或零時差漏洞是指軟體或硬體中還沒有有效修補程式的安全漏洞,並且其供應商通常不知曉,而零日攻擊或零時差攻擊則是指利用這種漏洞進行的攻擊。(ref)
要補充的是,每間公司、產品都應依自己的資安需求選擇適合的防護,也就是風險胃納(Risk appetite),願意接受多少的風險,雖然越多防禦越安全,但多一層保護就是多一層成本,不是每個產品都需要嚴密防護,例如技術部落格只呈現靜態資訊,被 XSS 影響不大,也不須思考 CSP 或如何降低損害,但如果是加密貨幣交易所冷錢包,就需要嚴密防護,因為被偷走會損失很大。雖然不是每個產品都需嚴密防護,但知道各種防禦層次仍有好處,這樣就能在需要防護手段時,立刻知道可選用的解決方案、這些方案的成本與效益,知道越多,越能知道該導入或不導入。
既然要假設 XSS 必然發生,那就要先來看看攻擊者達成 XSS 後可以做什麼?攻擊者達成 XSS 後,可以…
- 偷驗證身份用的 token
- 直接呼叫 API,進行危險/敏感操作,如:改密碼、轉帳
- 偷隱私資料,如:個人身份資料、交易紀錄
若要降低被 XSS 後的影響,就要想辦法減少攻擊者可做的事,也就是讓攻擊者難以做到上述這些事。
第一招:最有效的解法 — 多重驗證#
為何 XSS 後攻擊者可進行危險操作?攻擊者可拿 token 去向後端發送請求,而後端會因為收到的請求內有可驗證身分的 token,因而信任這請求、認為這是本人發出,因此執行對應操作。
因此解決方式是引入多重驗證,後端除了要求 token、還需要求其他只有本人知道的資訊,讓後端不要只依據 token 來信任這是本人發出的。多重驗證的案例例如銀行轉帳會多一道手續,要求輸入網銀密碼或簡訊驗證碼、或是修改密碼要輸入現在的密碼。
多重驗證的優點:
- 保護重大操作不被 XSS 攻擊,提高安全性
- 即使有人實體接觸使用者的電腦,也沒辦法做壞事
多重驗證的缺點:
- 安全性與使用者體驗成反比,安全性越高,體驗越差
舉例來說,如果每做一個操作、打一隻 API 就要收一次簡訊,使用者會覺得很麻煩、體驗很差,因此目前大多數是只有重大操作才需雙重驗證,一般取資料(e.g. 使用者資料、交易紀錄)的 API 則不保護。
第二招:不讓 token 被偷走#
先說明一點,這裡所說的 token 不指定特定技術,可視為一個「可驗證身份的東西」即可~
雖然 token 有沒有被偷走,攻擊者都可以向後端發請求,以你的身分操作,但兩者還是有差異的,簡單說明如下:
有無拿到 token 的相同處#
- 都可以向後端發請求,以你的身分操作
- 拿到 token:攻擊者可用你的身分 token 發請求
- 拿不到 token:拿不到 HttpOnly cookie,可發
fetch請求,會在請求時自動帶上 token
有無拿到 token 的相異處#
- 會不會被網站限制住
- 拿到 token:可在任何地方發請求
- 拿不到 token:只能在 XSS 的攻擊點執行惡意程式碼,如果只能在攻擊點執行,可能會有限制如 payload 字數限制或同源政策限制
- 會不會有時間限制
- 拿到 token:只要 token 沒過期,就可在自己電腦以使用者身分發請求
- 拿不到 token:只有使用者開啟網頁時能執行攻擊,若使用者把網頁、瀏覽器關掉,就不能再執行 JavaScript
上面所說的同源政策限制,舉例來說,a.monica.tw 跟 b.monica.tw 都用 monica.tw 的 cookie 驗證,如果攻擊者在 a.monica.tw 找到 XSS 但使用者資料在 b.monica.tw,那攻擊者會因為同源政策而無法在 a fetch 拿到 b 的資料;但如果兩個服務共用同一 token 且 token 存在 localStorage,攻擊者就可拿到 token 再去存取 b,取得使用者資料。
從上面有無拿到 token 的差異比較,可看出 token 不被偷走,會讓攻擊更侷限,因此我們要想辦法盡量讓 token 不被偷走。
token 儲存方式#
在目前前端機制中,保證 token 不被 JavaScript 存取的唯一方法就是HttpOnly 的 cookie(不考慮瀏覽器本身漏洞、不考慮有 API 直接回傳 token)。
而如果只想讓部分 JavaScript 拿到 token 呢?可考慮兩種方式:
1. 用 closure 方式儲存#
將 token 存在 JavaScript 變數內,且用 closure 把變數包住,確保外界存取不到,範例程式碼如下:
const API = (function() { let token return { login(username, password) { fetch('/api/login', { method: 'POST', body: JSON.stringify({ username, password }) }).then(res => res.json()) .then(data => token = data.token) },
async getProfile() { return fetch('/api/me', { headers: { 'Authorization': 'Bearer ' + token } }) } }})()
// 使用時API.login()API.getProfile()此方式的優點是即使攻擊者找到 XSS,也無法「直接」存取 token,而會說無法「直接」存取,是因為可以間接存取到,攻擊者可修改 window.fetch 方法,存取傳入函式的參數,間接拿到 token。
window.fetch = function(path, options) { console.log(options?.headers?.Authorization)}API.getProfile()此方式的缺點除了攻擊者可間接存取、不全然安全外,另一個缺點就是token 不能持久化,重新整理後就會不見。
2. context isolation,讓 XSS 無法干擾有 token 的執行環境#
如果只想讓部分 JavaScript 拿到 token,更安全的方式是 context isolation,讓 XSS 無法干擾有 token 的執行環境,可以用 Web Workers 建立新執行環境,把 API 請求都放在 worker 內,示意圖如下。
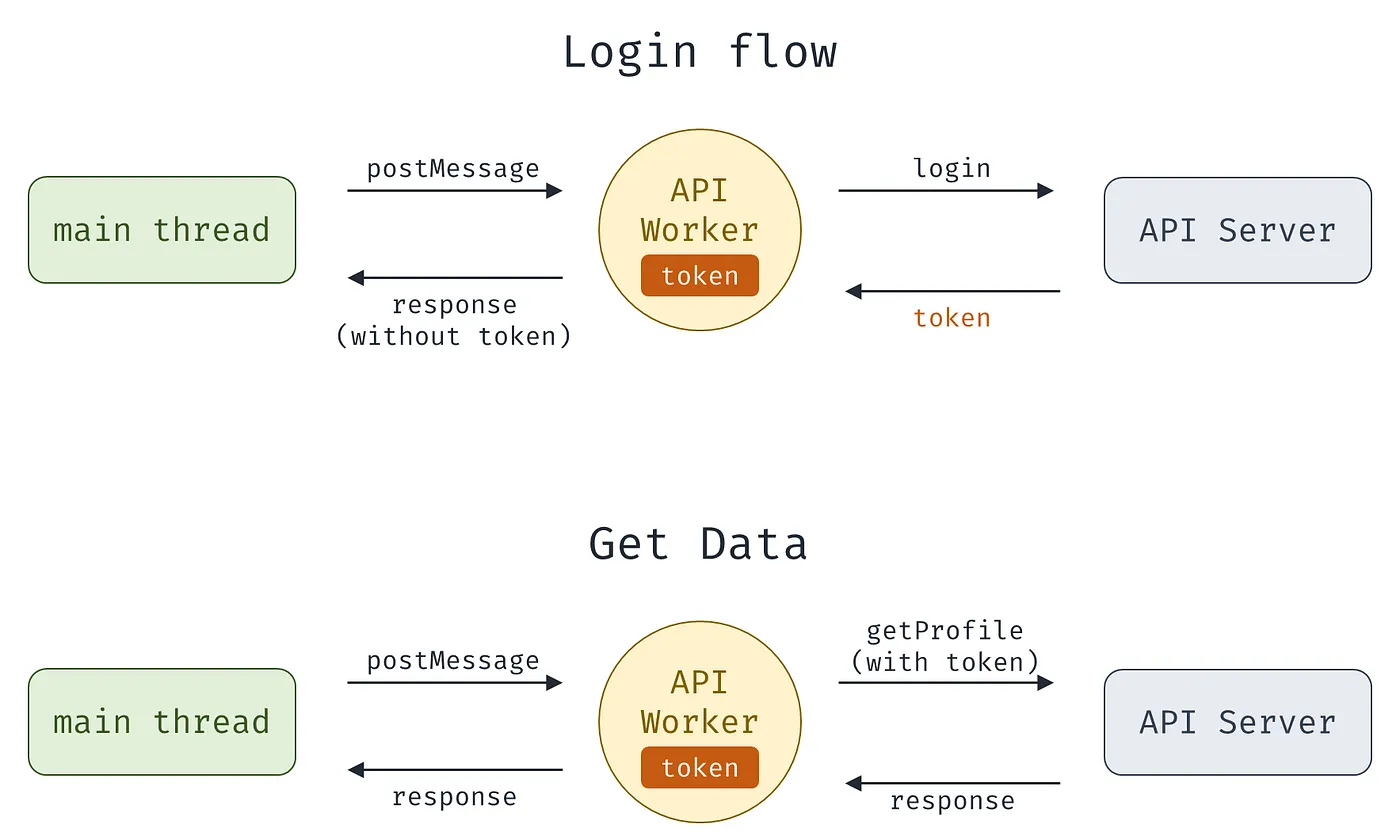
關於 Web Worker 的程式碼範例,可參考 Huli 的文章這裡有概念性的程式碼示例,因為我也還沒試著自己寫過,就不放上來了~
此方式的優點是能隔離執行環境,除非 worker 內有 XSS,否則 main thread 無法干擾 worker、拿不到 worker 內資料,可保證 token 安全性。缺點則是增加開發成本,且一樣 token 不能持久化。
以 Web Worker 實作的實際案例可參考日本二手商品交易平台 Mercari,詳細解說可看這篇文章 Building secure web apps using Web Workers。
若要在 JavaScript 拿到 token,又不須持久化,Web Worker 應該是最佳解。
第三招:限制 API 的呼叫#
前面有提過,如果 token 偷不走,攻擊者仍可透過 XSS 呼叫 API。而偷不走可分為兩種狀況:
- 使用 HTTP only cookie:此時攻擊者可呼叫的 API 不受限,他可用
fetch()呼叫 API,請求時就會自動帶上 cookie - 使用 Web Workers 與變數儲存 token:此時攻擊者可呼叫的 API 有限,他不能以
fetch呼叫 API ,因為不會自動帶上 token,所有請求都要經過 Web Workers,攻擊者只能呼叫 Web Workers 內有實作的 API。舉例來說,後端伺服器有/uploadFile功能,但前端 worker 內沒實作,攻擊者因此無法呼叫到/uploadFile的功能。
由上也可看出,即使 token 偷不走,不同的 token 儲存方式也會影響攻擊者能呼叫的 API 範圍,限制越多的 API 呼叫,就越能提高安全性。
第四招:限制 token 的權限#
雖然 token 無法被拿走是最好的,但如果要再多一層防護,我們還可以再思考,假設 token 一定會被拿走、利用,我們還能做什麼?
我們可以限制 token 的權限。
舉例來說,有個餐廳訂位系統的應用,後端提供的 API 是讓前後台都共用同 API 伺服器,例如 /users/me 是拿自己的資料,/internal/users 拿所有使用者資料(會檢查權限),這時若 XSS 攻擊發生在前台訂餐廳網站,攻擊對象是內部員工,攻擊者就能用 /internal/users 拿所有使用者資料。
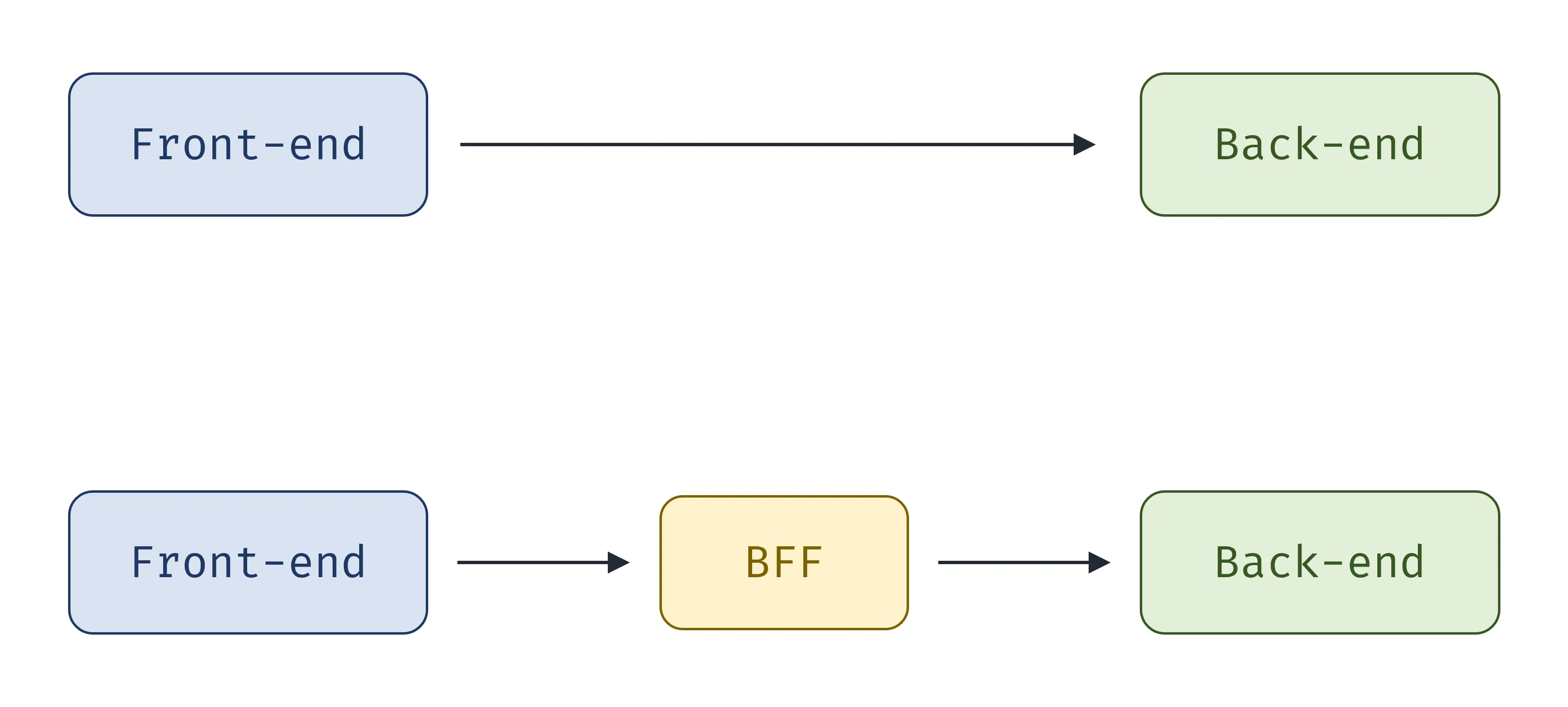
解決方式有兩種,解法一是將後端 API 切分為內部系統與訂位系統,但此方式改動成本太高;此時可考慮解法二,採用 Backend For Frontend(BFF),讓所有前端請求都先經過 BFF,因此攻擊者在前端拿到的 token 只是跟 BFF 溝通的 token,不是和後端伺服器溝通的 token,就可透過 BFF 限制前端 token 權限,即使攻擊者拿到 token 也無法呼叫內部 API。
小結#
「防止 XSS」是一定要做的,但只是第一道防線,因為只防止 XSS,防禦是全有或全無,全有就是全部防禦成功,全無則是只要一個地方沒防好,等於沒防禦,因此第二、三道防線可避免防禦 XSS 的「全有或全無」,即使忘記過濾使用者輸入,還有 CSP 阻擋 JavaScript 的執行,即使 CSP 被繞過,還有限制影響範圍,透過雙重驗證保護敏感操作。
但安全性與成本、系統複雜度成正相關,越多防線也需要越多成本,雖然我們了解很多防禦手段,但不代表每個產品都需要這樣防禦,還是要視情況而定。
Reference:#
- https://aszx87410.github.io/beyond-xss/ch2/xss-defense-sanitization/
- https://aszx87410.github.io/beyond-xss/ch2/xss-defense-csp/
- https://aszx87410.github.io/beyond-xss/ch2/token-storage/
- https://zh.wikipedia.org/zh-tw/%E7%91%9E%E5%A3%AB%E5%A5%B6%E9%85%AA%E7%90%86%E8%AE%BA
如有任何問題歡迎聯絡、不吝指教✍